
|
|
| Important |
Distributed apps are much more complex than apps in which all components run in the same JVM. Performance is among the most important of the many reasons to avoid adopting a distributed architecture unless it's the only way to satisfy business requirements. |
The commonest cause of disappointing performance in J2EE apps is unnecessary use of remote calling - usually in the form of remote access to EJBs. This typically imposes an overhead far greater than that of any other operation in a J2EE app. Many developers perceive J2EE to be an inherently distributed model. In fact, this is a misconception. J2EE merely provides particularly strong support for implementing distributed architectures when necessary. Just because this choice is available doesn't mean that we should always make it. In this section, we'll look at why remote calling is so expensive, and how to minimize its effect on performance when we must implement a distributed app.
Whereas ordinary Java classes make calls by reference to objects in the same virtual machine, calls to EJBs in distributed apps must be made remotely, using a remote invocation protocol such as HOP. Clients cannot directly reference EJB objects and must obtain remote references usingJNDI. EJBs and EJB clients may be located in different virtual machines, or even different physical servers. This indirection sometimes enhances scalability: because an app server is responsible for managing naming lookups and remote method invocation, multiple app server instances can cooperate to route traffic within a cluster and offer failover support. However, the performance cost of remote, rather than local, calling can be hefty if we do not design our apps appropriately. EJB's support for remote clients is based on Java RMI. However, any infrastructure for distributed invocation will have similar overheads. Java RMI supports two types of objects: remote objects, and serializable objects. Remote objects support method invocation from remote clients (clients running in different processes), who are given remote references to them. Remote objects are of classes that implement the java.rmi. Remote interface and all of whose remote methods are declared to throw java.rmi.RemoteException in addition to any app exceptions. All EJBs with remote interfaces are remote objects. Serializable objects are essentially data objects that can be used in invocations on remote objects. Serializable objects must be of classes that implement the java.io.Serializable tag interface and must have serializable fields (other serializable objects, or primitive types). Serializable objects are passed by value, meaning that both copies can be changed independently, and that object state must be serialized (converted to a stream representation) and deserialized (reconstituted from the stream representation) with each method call. Serializable objects are used for data exchange in distributed J2EE apps, as parameters, return values, and exceptions in calls to remote objects. Method invocations on remote objects such as EJB objects or EJB homes always require a network round trip from client to server and back. Hence remote calling consumes network bandwidth. Unnecessary remote calls consume bandwidth that should be reserved for operations that do something necessary, such as moving data to where it's needed. Each remote call will encounter the overhead of marshaling and unmarshaling serializable parameters: the process by which the caller converts method parameters into a format that can be sent across the network, and the receiver reassembles object parameters. Marshaling and unmarshaling has an overhead over and above the work of serialization and deserialization and the time taken to communicate the bytes across the network. The overhead depends on the protocol being used, which may be HOP or an optimized proprietary protocol such as WebLogic's T3 or Orion's ORMI.J2EE 1.3 app servers must support HOP, but need not use it by default. The following diagram illustrates the overhead involved in remote method invocation:
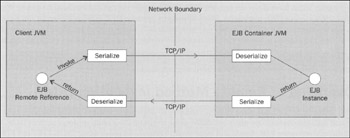
This overhead means that remote calls may be more than 1,000 times slower than local calls, even if there's a fast LAN connection between the app components involved.
| Important |
The number of remote calls is a major determinant - potentially the major determinant -of a distributed app's performance, because the overhead of remote calling is so great. |
In the following section, we'll look at how we can minimize the performance impact of remote invocation when designing distributed apps. Fortunately, we have many choices as architects and developers. For example:
We can try to structure our app to minimize the need to move data between architectural tiers through remote calling. This technique is known as app partitioning.
Let's examine these techniques in turn.
The greatest scope for performance gains is in structuring an app so as to minimize the number of remote calls that will be required.
app partitioning is the task of dividing a distributed app into major architectural tiers and assigning each component to one tier. In a J2EE web app using EJB, this means assigning each object or functional component to one of the client browser, the web tier, the EJB tier, or the database. A "functional component" need not always be a Java object. For example, a stored procedure in a relational database might be a functional component of an app. app partitioning will determine the maximum extent of network round trips required as the app runs. The actual extent of network round trips may be less in some deployment configurations. A distributed J2EE app must support different deployment configurations, meaning that the web container and EJB container may be collocated in the same JVM, which will reduce the number of network round trips in some deployments. The main aim of app partitioning is to ensure that each architectural layer has a clearly defined responsibility. For example, we should ensure that business logic in a distributed J2EE app is in the EJB tier, so that it can be shared between client types. However, there is also a performance imperative: to ensure that frequent, time-critical operations can be performed without network round trips. As we've seen from examining the cost of Java remote method invocations, app partitioning can have a dramatic effect on performance. Poor app partitioning decisions lead to "chatty" remote calling - the greatest enemy of performance in distributed apps. Design and performance considerations with respect to app partitioning tend to be in harmony. Excessive remote calling complicates an app and is error prone, so it's no more desirable from a design perspective than a performance perspective. However, app partitioning sometimes does involve tradeoffs.
| Important |
Appropriate app partitioning can have a dramatic effect on performance. Hence it's vital to consider the performance impact of each decision in app partitioning. |
The greatest performance benefits will result from minimizing the depth of calling down a distributed J2EE stack to satisfy incoming requests.
| Important |
The deeper down a distributed J2EE stack calls need to be made to service a request, the poorer the resulting performance will be. Especially in the case of common types of request, we should try to service requests as close as possible to the client. Of course, this requires a tradeoff: we can easily produce hosts of other problems, such as complex, bug-prone caching code or stale data, by making this our prime goal. |
What techniques can we use to ensure efficient app partitioning? One of the biggest determinants is where the data we operate on comes from. First, we need to analyze data flow in the app. Data may flow from the data store in the EIS tier to the user, or from the user down the app's tiers. Three strategies are particularly useful for minimizing round trips:
Moving data to where we operate on it.
The worst situation is to have data located in one tier while the operations on it are in another. For example, this arises if the web tier holds a data object and makes many calls to the EJB tier as it processes it. A better alternative is to move the object to the EJB tier by passing it as a parameter, so that all operations run locally, with only one remote invocation necessary. The EJB Command pattern, discussed in , is an example of this approach. The Value Object pattern also moves entire objects in a single remote call.
Caching, which we have discussed, is a special case of moving data to where we operate on it. In this case, data is moved in the opposite direction: from EIS tier towards the client.
An example of this strategy is using a single stored procedure running inside a relational database to implement an operation instead of performing multiple round trips between the EJB tier and the database to implement the same logic in Java and SQL. In some cases this will greatly improve performance. The use of stored procedures is an example of a performance-inspired app partitioning decision that does involve a tradeoff. It may have other disadvantages. It may reduce the portability of the app between databases, and may reduce maintainability. However, this app partitioning technique is applicable to collocated, as well as distributed, J2EE apps. Another example is a possible approach to validating user input. Validation rules are business logic, and therefore belong naturally in the EJB tier in a distributed app, not the web tier. However, making a network round trip from the web container to the EJB container to validate input each time a form is submitted will be wasteful, especially if many problems in the input can be identified without access to back-end components. One solution is for the EJB tier to control validation logic, and move validation code to the web tier in a serializable object implementing an agreed validation interface. The validator object need only be passed across the network once. As the web tier will already have the class definition of the validator interface, only the implementing class need be provided by the EJB tier at run time. The validator can then be invoked locally in the web tier, and remote calls will only be necessary for the minority of validation operations, such as checking a username is unique, that require access to data. As local calling is so much faster than remote calling, this strategy is likely to be more performant than calling the EJB tier to perform validation, even if the EJB tier needs to perform validation again (also locally) to ensure that invalid input can never result in a data update. Let's look at an illustration of this in practice. Imagine a requirement to validate a user object that contains e-mail address password, postcode, and username properties. In a naive implementation a web tier controller might invoke a method on a remote EJB to validate each of these properties in turn, as shown in the following diagram:
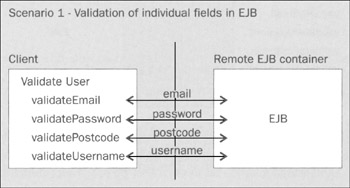
This approach will guarantee terrible performance, with an excessive number of expensive remote calls required to validate each user object. A much better approach is to move the data to where we operate on it (as described above), using a serializable value object so that user data can be sent to the EJB server in a single remote call, and the results of validating all fields returned. This approach is shown in the diagram below:
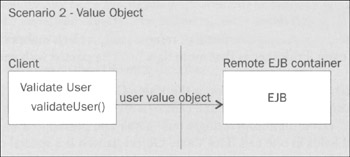
This will deliver a huge performance improvement, especially if there are many fields to validate. Performing just one remote method invocation, even if it involves passing more data, will be much faster than performing many fine-grained remote method invocations. However, let's assume that the validation of only the username field requires database access(to check that the submitted username isn't already taken by another user), and that all other validation rules can be applied entirely on the client. In this case, we can apply the approach described above of moving the validation code to the client via a validation class obtained from the EJB tier when the app starts up. As the app runs, the client-side validator instance can validate most fields, such as e-mail address and postcode, without invoking EJBs. It will need to make only one remote call, to validate the username value, to validate each user object. This scenario is shown in the diagram overleaf:
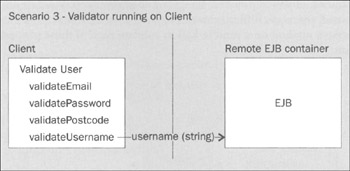
Since only a single string value needs to be serialized and deserialized during the validation of each user object, this will perform even better than the value object approach, in which a larger value object needed to be sent across the wire. Yet it still allows the EJB implementation to hide the validation business rules from client code. A more radical app of the principle of moving validation code to the data it works on is to move validation logic into JavaScript running in the browser, to avoid the need for communication with the server before rejecting some invalid submissions. However, this approach has other disadvantages that usually preclude its use.
| Note |
We discussed the problem of validating input to web apps, with practical examples, in . |
Due to the serialization and marshaling overhead of remote calls, it often makes sense to minimize the number of remote calls, even if this means that more data must be passed with each call. A classic scenario for method call consolidation is the Value Object pattern, which we saw in the above example. Instead of making multiple fine-grained calls to a remote EJB to retrieve or update data, a single serializable "value object" is returned from a single bulk getter and passed to a single bulk setter method, retrieving or updating all fields in one call. The Value Object pattern is a special case of the general rule that remote objects should not have interfaces that force clients into "chatty" access.
| Important |
Minimizing the number of remote calls will improve performance, even if more data needs to be passed with each remote call. Each operation on an EJB's remote interface should perform a significant operation. Often it will implement a single use case. Chatty calling into the EJB container will usually result in the creation of many transaction contexts, which also wastes resources. |
While minimizing the number of remote calls is usually the most profitable area to concentrate on, sometimes we may be able to reduce the overhead of transmitting across the network data that must be exchanged.
Since all parameters in remote invocations must be serialized and deserialized, the performance of serialization is critical. While core Java provides transparent serialization support that is usually satisfactory, occasionally we can usefully put more effort into ensuring that serialization is as efficient as possible, by applying the following techniques to individual serializable objects.
By default, all fields of serializable objects other than transient and static fields will be serialized. Thus by marking as transient "short-lived" fields - such as fields that can be computed from other fields - we can reduce the amount of data that must be serialized and deserialized and passed over the network.
| Important |
Any "short-lived" fields of serializable objects can be marked as transient. However, use this approach only with great care. The values of transient fields will need to be reset following deserialization; failing to do so is a potential cause of subtle bugs. |
We may also be able to represent the data we need in a more efficient manner. Serializing primitives is much faster, and requires much less network bandwidth, than serializing objects. Thus any object that can be represented as a primitive type is a prime candidate for more efficient representation in a serializable object, saving memory as well as optimizing serialization. The classic example is java.util.Date, which can usually be replaced by a long system time in milliseconds. If we can represent Date objects as long in serializable objects, we will usually see a significant improvement in serialization performance and a reduction in the size of the serialized objects. The following table shows the effect of serializing the data in 10,000 dates in three different ways. Two implementations were used of the following interface:
interface DateHolder extends java.io.Serializable {
Date getDate();
}
The first implementation, DateDateHolder, held the date as a java.util.Date. The second implementation, LongDateHolder,used a long to represent the date. The third row of data is the result of doing away with the 10,000 objects altogether, and using an array of 10,000 longs containing the same information. This produced an even more dramatic improvement in performance:
|
10,000 serializations, written to a disk file |
Time (ms) |
Size of file (kb) |
Time as percentage of unoptimized case |
Data size as % of unoptimized case |
|---|---|---|---|---|
|
|
||||
|
Object holding a java.util.Date object |
370 |
225 |
100% |
100% |
|
Object holding long system time |
110 |
137 |
30% |
61% |
|
Array of long system times |
5 |
79 |
1% |
35% |
Of course, this kind of optimization may have unintended consequences. If there is a need for repeated conversion to and from a primitive type, its overhead may outweigh the serialization benefit. Also, there is a danger of unduly complicating code. On the whole, it is consistent with good design and often proves a worthwhile optimization.
| Important |
Primitives are much faster to serialize and deserialize than objects. If it's possible to replace an object by a primitive representation, it is likely to improve serialization performance dramatically. |
It's also important to realize what we don't need to worry about with standard serialization. Developers sometimes wonder what happens if they serialize a "big" class, which contains many methods. The serialization process does not communicate .class files, so the executable code will not eat up bandwidth. The class will need to be loaded by the receiver, so it may need to be passed once over the network, if it is not locally available; this will be a small, one-off cost. Serializing a class that is part of an inheritance hierarchy - for example, serializing a class C that extends class B that extends class A - adds a little overhead to the serialization process (which is based on reflection, so will need to traverse all class definitions in the inheritance hierarchy), but doesn't increase the amount of data that will be written out, beyond the additional fields of the superclasses. Similarly, static fields do not bloat the size of the serialized representation of a class. These will not be serialized. The sender and receiver will maintain separate copies of static fields. Any static initializers will run independently, when each JVM loads the class. This means that static data can get out of sync between remote JVMs, one of the reasons for the restrictions on the use of static data in the EJB specification.
An important optimization of the default serialization implementation concerns multiple copies of the same object serialized to the same stream. Each object written to the stream is assigned a handle, meaning that subsequent references to the object can be represented in the output by the handle, not the object data. When the objects are instantiated on the client, a faithful copy of the references will be constructed. This may produce a significant benefit in serialization and deserialization time and network bandwidth in the case of object graphs with multiple connections between objects.
In some cases it's possible to do a more efficient job - with respect to serialization and deserialization speed and the size of serialized data - than the default implementation. However, unlike the choices we've just discussed, which are fairly simple to implement, this is not a choice to be taken lightly. Overriding the default serialization mechanism requires custom coding, in place of standard behavior. The custom code will also need to be kept up-to-date as our objects - and possibly, inheritance hierarchy - evolve. There are two possible techniques here. The first involves implementing two methods in the serializable class. Note that these methods are not part of any interface: they have a special meaning to the core Java serialization infrastructure. The method signatures are:
private void writeObject (java.io.ObjectOutputStream out) throws IOException; private void readObject (java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
The writeObject() method saves the data held in the object itself. This doesn't include superclass state, which will still be handled automatically. It does include associated objects, whose references are held in the object itself. The readObject() method is called instead of a constructor when an object is read from an ObjectInputStream. It must set the values of the class's fields from the stream. These methods will use the Serialization API directly to write objects to the ObjectOutputStream supplied by the serialization infrastructure and restore objects from the ObjectInputStream. This means that more implementation work is involved, but the class has control over the format of its data's representation in the output stream. It's important to ensure that fields are written and read in the correct order. Overriding readObject and writeObject can deliver significant performance gains in some cases, and very little in others. It eliminates the reflection overhead of the standard serialization process (which may not, however, be particularly great), and may allow us to use a more efficient representation as fields are persisted. Many standard library classes implement readObject() and writeObject(), including java.util.Date, java.util.HashMap, java.util.LinkedList, and most AWT and Swing components. In the second technique, an object can gain complete control over serialization and deserialization if it implements the java.io.Externalizable interface. This is a subclass of the Serializable tag interface that contains two methods:
public void writeExternal (ObjectOutput out) throws IOException public void readExternal (ObjectInput in) throws IOException, ClassNotFoundException
In contrast to a Serializable object implementing readObject and writeObject, an Externalizable object is completely responsible for saving and restoring its state, including any superclass state. The implementations of writeExternal and readExternal will use the same API as implementations of writeObject and readObject.
| Note |
While constructor invocation is avoided when a serializable object is instantiated as a result of standard deserialization, this is not true for externalizable objects. When an instance of an externalizable class is reconstructed from its serializable representation, its no-argument constructor is invoked before readExternal() is called. This means that we do need to consider whether the implementation of the no argument constructor may prove wasteful for externalizable objects. This will also include any chained no argument constructors, invoked implicitly at run time. |
Externalizable classes are likely to deliver the biggest performance gains from custom serialization. I've seen gains of around 50% in practice, which may be worthwhile for the serializable objects most often exchanged in an app, if serializing these objects is proving a performance problem. However, externalizable classes require the most work to implement and will lead to the greatest ongoing maintenance requirement. It's usually unwise to make a class externalizable if it has one or more superclasses, as changes to the superclass may break serialization. However, this consideration doesn't apply to many value objects, which are not part of an inheritance hierarchy. Also, remember that an externalizable class may deliver worse serialization performance than an ordinary serializable class if it fails to identify any multiple references to a single object: remember that the default implementation of serialization assigns each object written to an OutputStream a handle that can be referred to later.
| Note |
The documentation with the JDK includes detailed information on advanced serialization techniques. I recommend reading this carefully before trying to use custom serialization to improve the performance of distributed apps. |
| Important |
Taking control of the serialization process is an example of an optimization that should be weighed carefully. It will produce performance benefits in most cases, and the initial implementation effort will be modest if we are dealing with simple objects. However, it decreases the maintainability of code. For example, we have to be sure that the persistent fields are written out and read in the same order. We have to be careful to handle object associations correctly. We also have to consider any class hierarchy to which the persistent class may belong. For example, if the persistent class extends an abstract base class, and a new field is added to it, we would need to modify our externalizable implementation. The standard handling of serialization enables us to ignore all these issues. Remember that adding complexity to an app's design or implementation to achieve optimization is not a one-off operation. Complexity is forever, and may cause ongoing costs in maintenance. |
We may not always want to transfer data in the form of serialized objects. Whatever means we choose to transfer large amounts of data, we will face similar issues of conversion overhead and network bandwidth. XML is sometimes suggested as an alternative for data exchange. Transferring data across a process boundary using serialized DOM documents is likely to be slower than converting the document to a string in the sender and parsing the string in the receiver. A serialized DOM document is likely to be much larger than the string representation of the same document. Bruce Martin discusses these issues in an article in JavaWorld, at http://www.javaworld.com/javaworld/jw-02-2000/jw-02-ssj-xml.html. Although it is likely, there is also no guarantee that a DOM document will even be serializable. For example, the Xalan 2 parser (a variant of which is used by WebLogic 6.1) allows the serialization of DOM documents, while the version of the Crimson parser used by Orion 1.5.2 does not. The org.w3c.dom interfaces are not themselves serializable, although most implementations will be. One option that does guarantee serializability is using the JDom, rather than DOM, API to represent the document: JDom documents are serializable (see http://www.jdom.org for further information about this alternative Java XML API). Thus I don't recommend use of XML to exchange data across network boundaries. As I said in , I believe that XML is best kept at the boundaries of J2EE apps. Another possibility is moving data in generic Java objects such as java.util.HashMap or javax.sql.RowSet. In this case it's important to consider the cost of serializing and deserializing the objects and the size of their serialized form. In the case of java.util.HashMap, which implements writeObject() and readObject(), the container itself adds little overhead. Simple timings can be used to determine the overhead of other containers.
However, the idea of communicating data from EJB tier to client in the form of a generic container such as a RowSet is unappealing from a design perspective. The EJB tier should provide a strongly typed interface for client communication. Furthermore, processing raw data from the EIS tier such as a RowSet may result in the discarding of some data, without it all needing to be sent to the client. This cannot happen if the client is always sent all the data and left to process it itself. Finally, the client becomes dependent on javax.sql classes that it would not otherwise need to use.
There is one way to eliminate much (but not all) of the overhead of distributed apps without writing a line of code: collocating the components on the same server so that they run in the same JVM. Where web apps are concerned, this means deploying the web tier and EJB tier in the same J2EE server. Most J2EE servers detect collocation and can use local calls in place of remote calls (in most servers, this optimization is enabled by default). This optimization avoids the overhead of serialization and remote invocation protocols. Both caller and receiver will use the same copy of an object, meaning that serialization is unnecessary. However, it's still likely to prove slower than invocation of EJBs through local interfaces, because of the container's need to fudge invocation semantics. This approach won't work for distributed app clients such as Swing clients, which can't run in the same JVM as a server process. But it's probably the commonest deployment option for EJBs with remote interfaces. I discussed this approach under the heading Phony Remote Interfaces in . As the title implies, it's an approach that's only valid if we know we need a distributed architecture, but the app at least initially can run with all its components collocated in the same JVM. There's a real danger that collocation can lead to the development of apps with RMI semantics that rely on call-by-reference and thus would fail in a truly distributed environment.
| Important |
If it's clear that collocation will always be the only deployment option, consider dispensing with the use of EJB (or at least EJB remote interfaces) and doing away with remoting issues once and for all. Flexible deployment is a key part of what EJB provides; when it's not necessary, the use of EJB may not be worthwhile. |
|
|