| Previous | Next
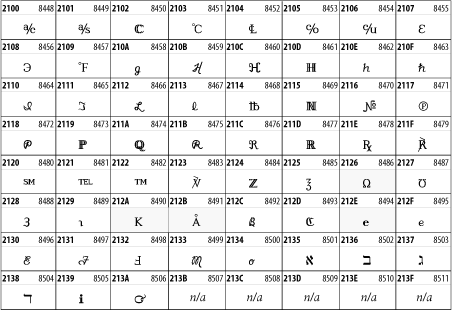
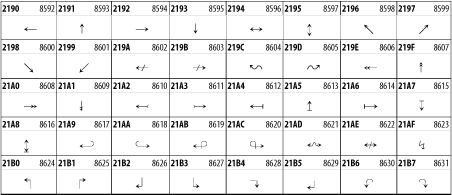
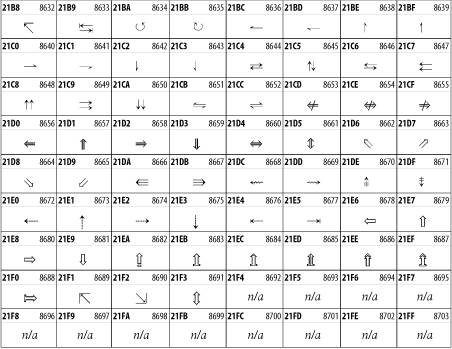
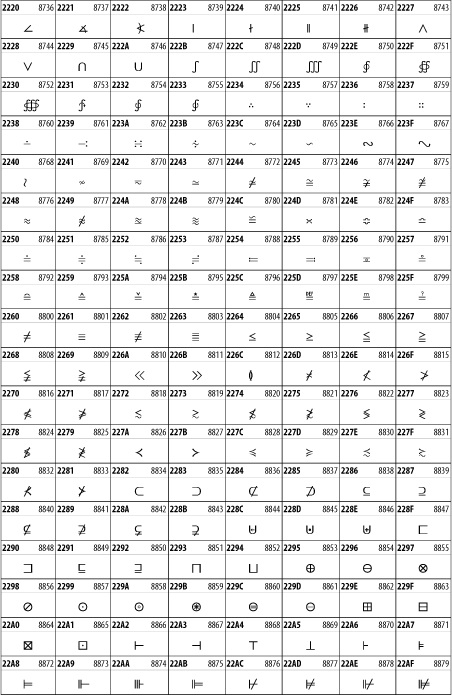
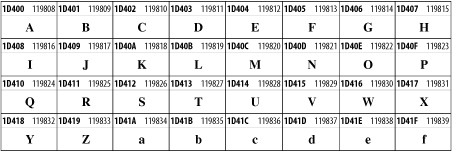
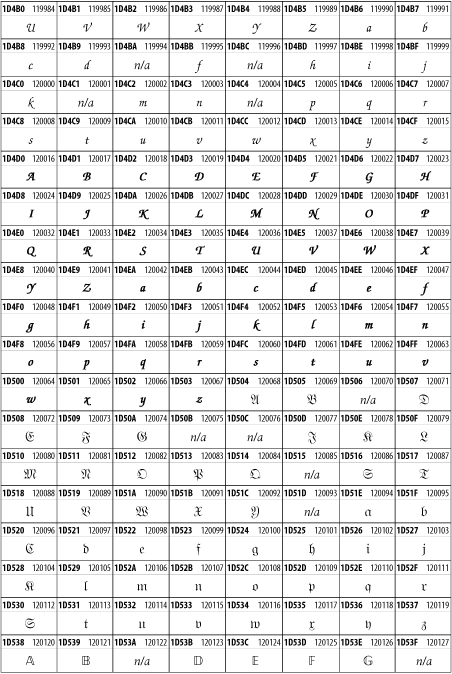
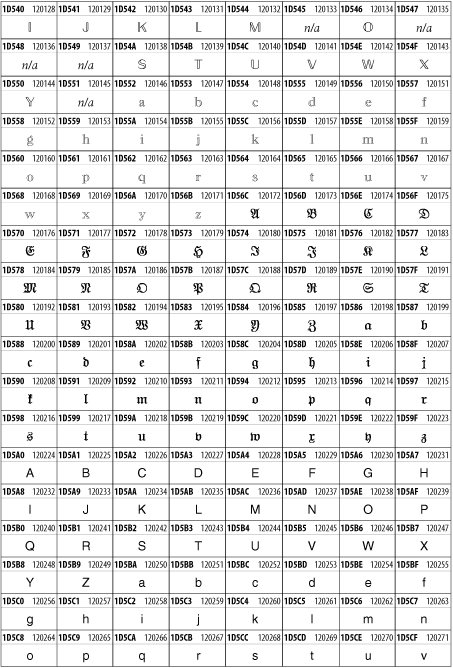
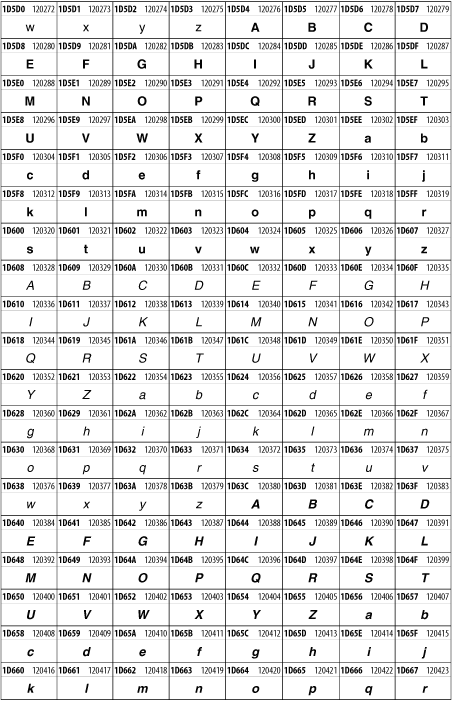
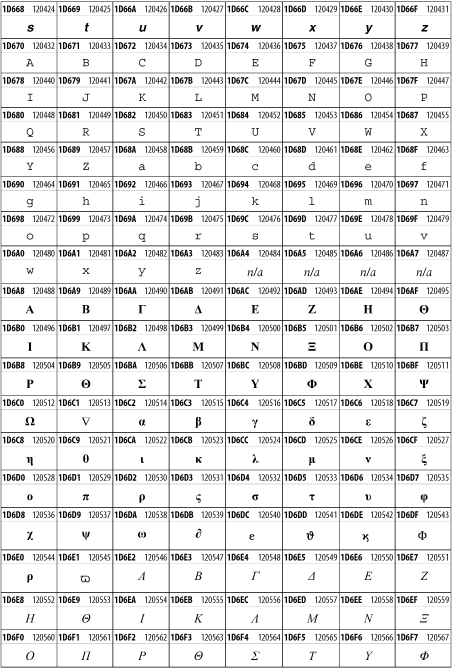
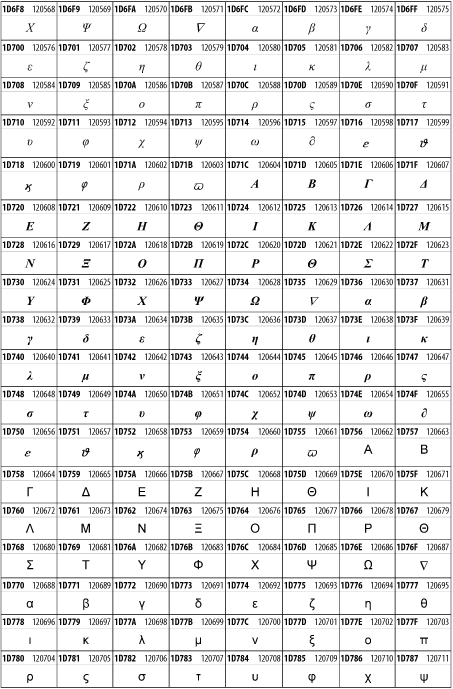
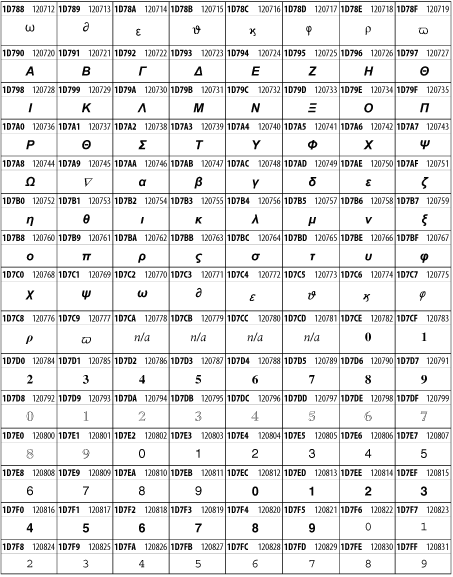
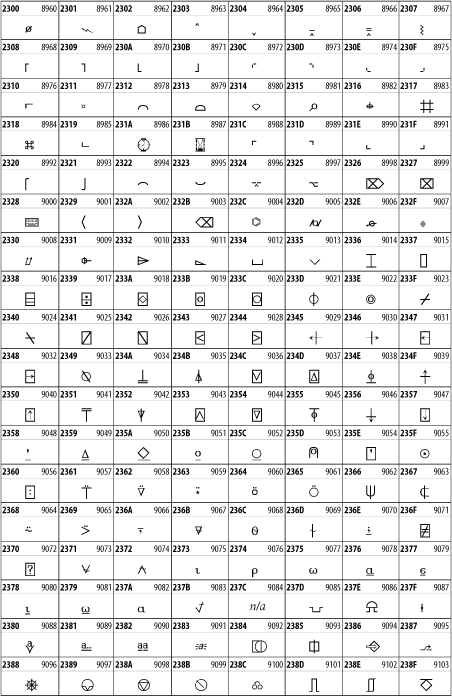
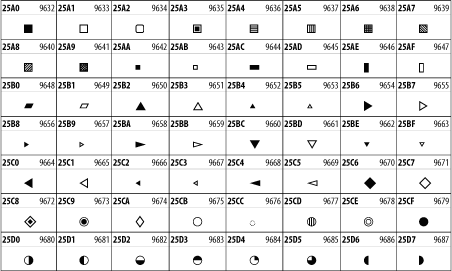
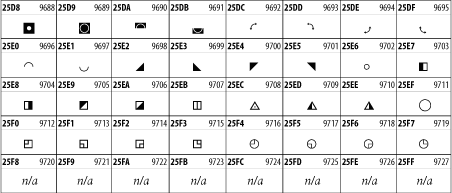
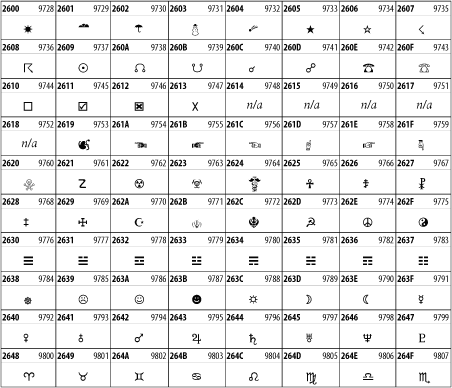
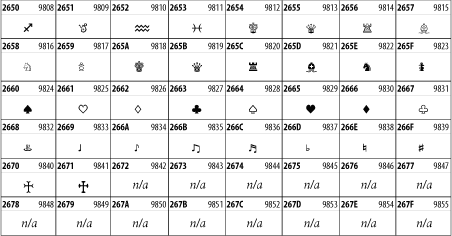
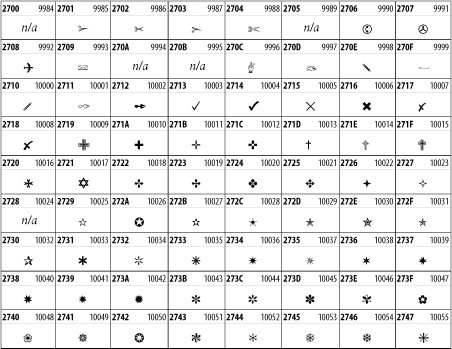
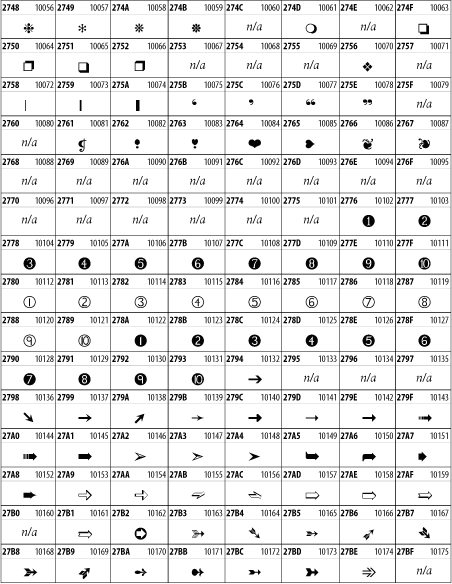
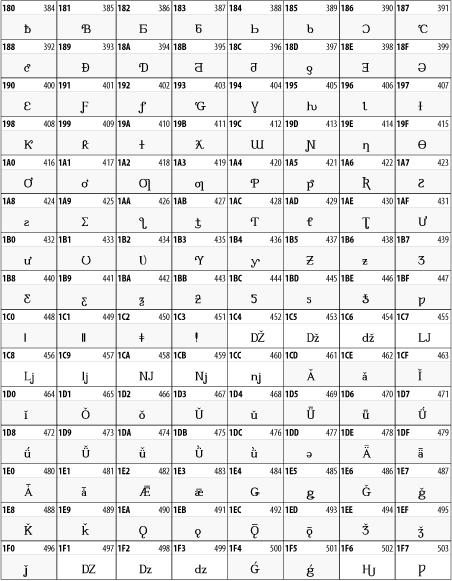
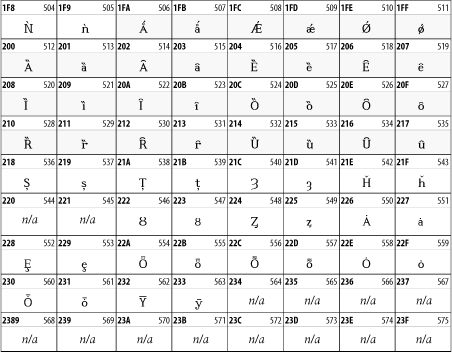
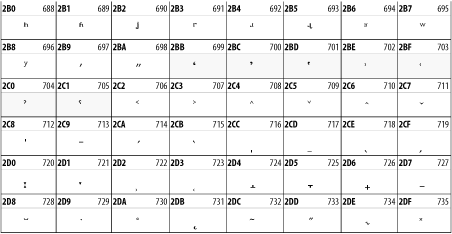
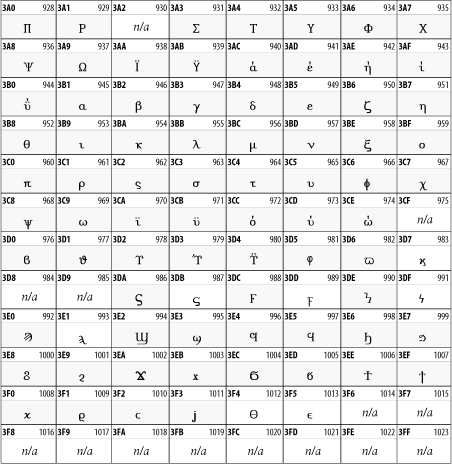
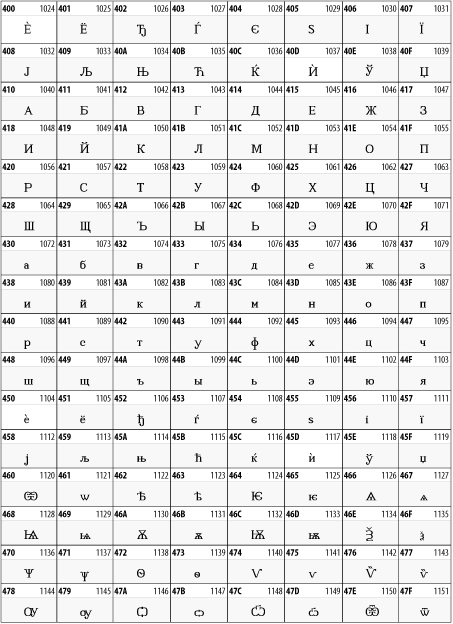
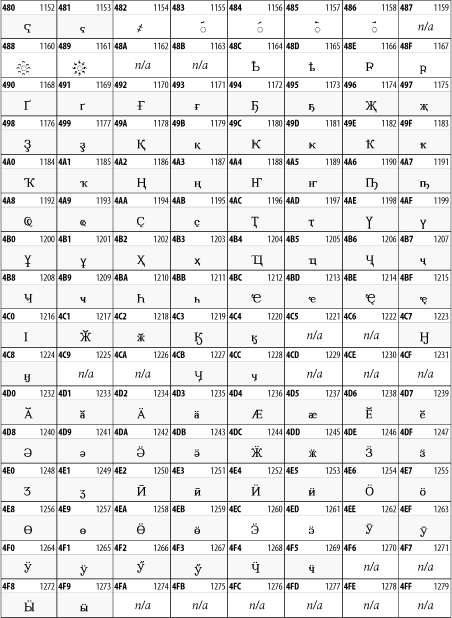
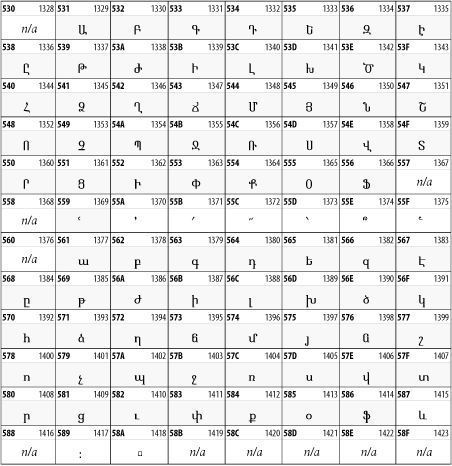
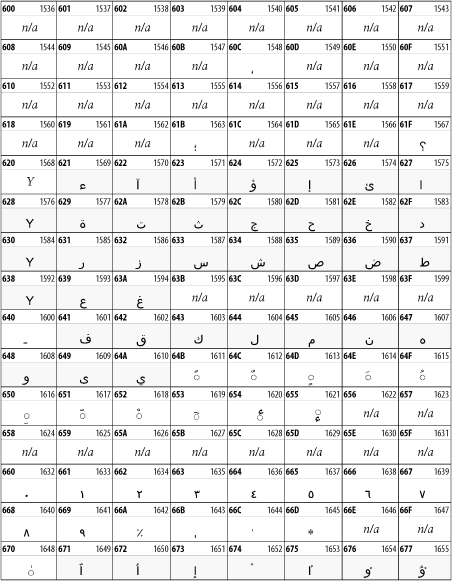
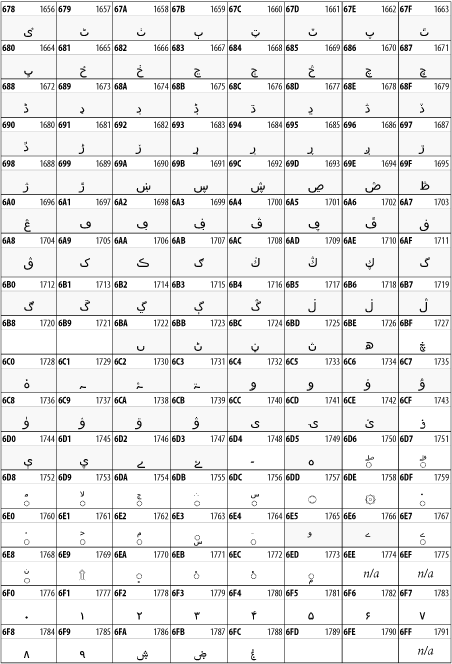
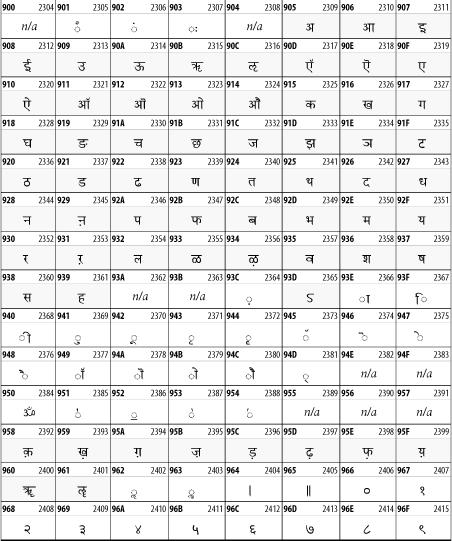
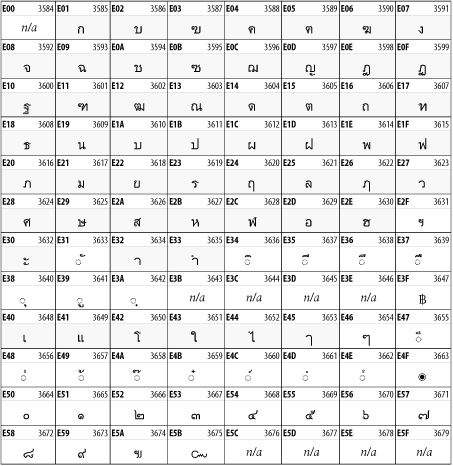
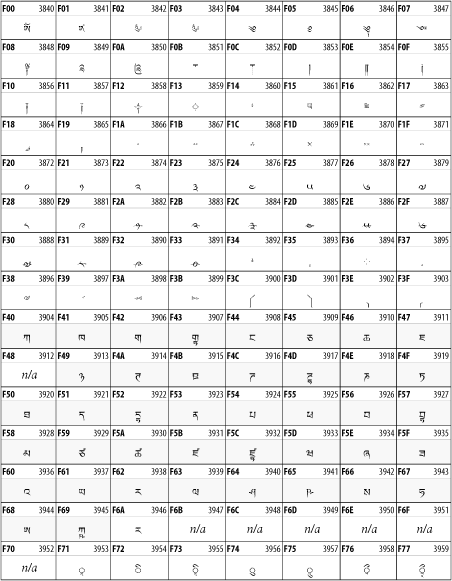
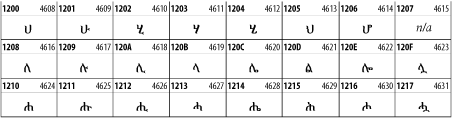
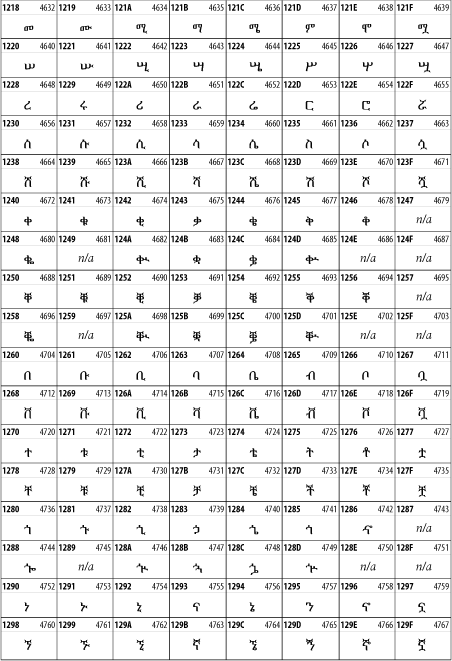
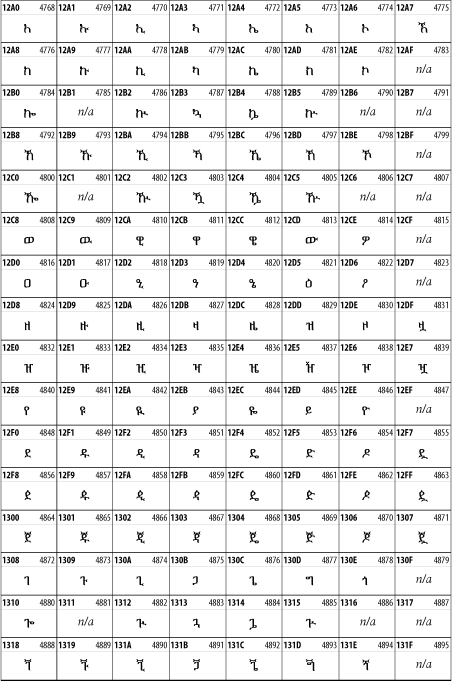
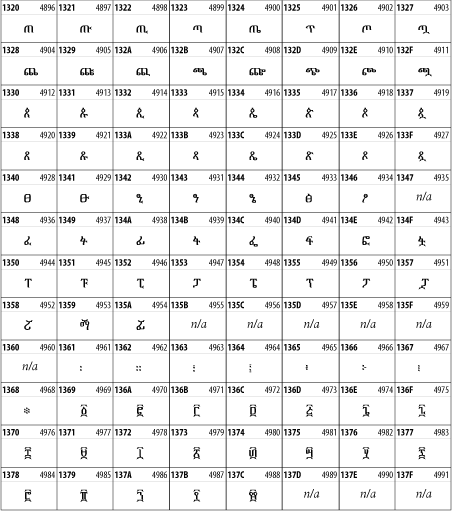
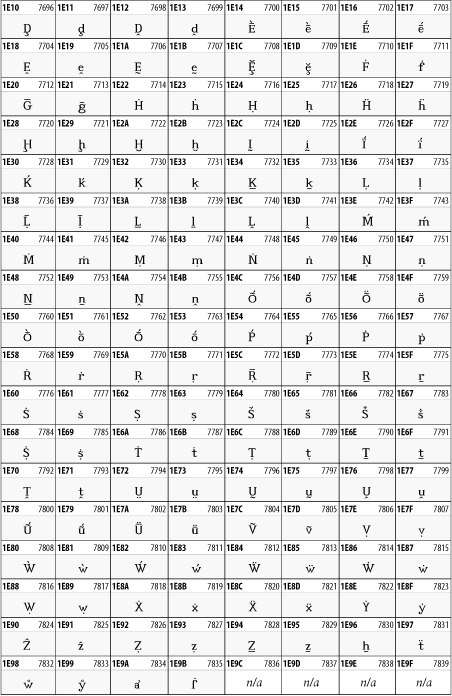
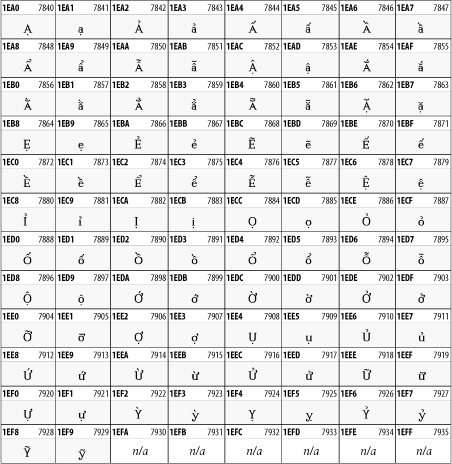
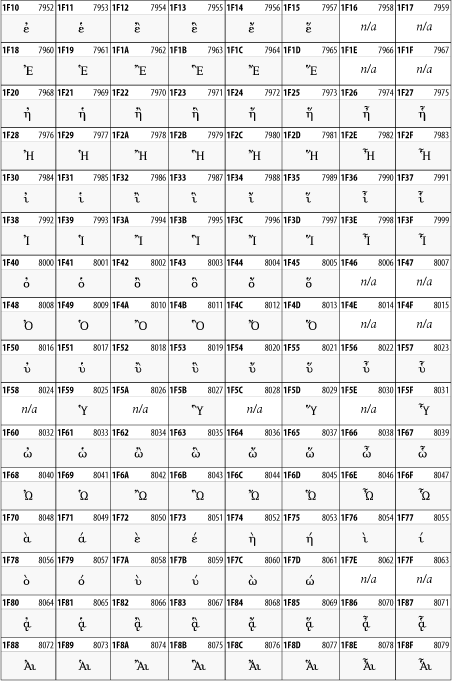
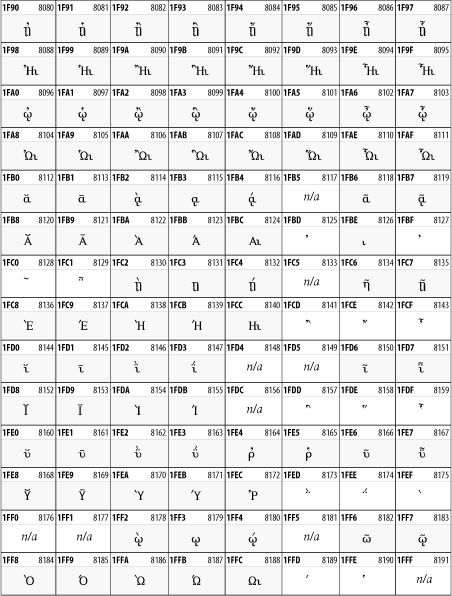
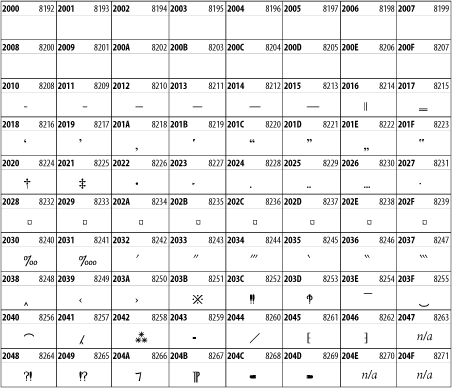
Other Unicode BlocksSo far we've accounted for a little over 300 of the more than 90,000 Unicode characters. Many thousands are still unaccounted for. Outside the ranges defined in XHTML and SGML, standard entity names don't exist. You should either use an editor that can produce the characters you need in the appropriate character set or you should use character references. Most of the 90,000-plus Unicode characters are either Han ideographs, Hangul syllables, or rarely used characters. However, we do list a few of the most useful blocks later in this chapter. Others can be found online at http://www.unicode.org/charts/ or in The Unicode Standard Version 3.0 by the Unicode Consortium (Addison Wesley, 2000). In the tables that follow, the upper lefthand corner contains the character's hexadecimal Unicode value, and the upper righthand corner contains the character's decimal Unicode value. You can use either value to form a character reference so as to use these characters in element content and attribute values, even without an editor or fonts that support them. Latin Extended-AThe 128 characters in the Latin Extended-A block of Unicode are used in conjunction with the normal ASCII and Latin-1 characters. They cover most European Latin letters missing from Latin-1. The block includes various characters you'll find in the upper halves of the other ISO-8859 Latin character sets, including ISO-8859-2, ISO-8859-3, ISO-8859-4, and ISO-8859-9. When combined with ASCII and Latin-1, this block lets you write Afrikaans, Basque, Breton, Catalan, Croatian, Czech, Esperanto, Estonian, French, Frisian, Greenlandic, Hungarian, Latvian, Lithuanian, Maltese, Polish, Provençal, Rhaeto-Romanic, Romanian, Romany, Sami, Slovak, Slovenian, Sorbian, Turkish, and Welsh. See Figure 26-7. Figure 26-7. Unicode's Latin Extended-A blockLatin Extended-BThe Latin Extended-B block of Unicode is used in conjunction with the normal ASCII and Latin-1 characters. It mostly contains characters used for transcription of non-European languages not traditionally written in a Roman script. For instance, it's used for the Pinyin transcription of Chinese and for many African languages. See Figure 26-8. Figure 26-8. The Latin Extended-B block of UnicodeIPA ExtensionsLinguists use the International Phonetic Alphabetic (IPA) to identify uniquely and unambiguously particular sounds of various spoken languages. Besides the symbols listed in this block, the IPA requires use of ASCII, various other extended Latin characters, the combining diacritical marks in Figure 26-11, and a few Greek letters. The block shown in Figure 26-9 only contains the characters not used in more traditional alphabets. Figure 26-9. The IPA Extensions block of UnicodeSpacing Modifier LettersThe Spacing Modifier Letters block, shown in Figure 26-10, includes characters from multiple languages and scripts that modify the preceding or following character, generally by changing its pronunciation. Figure 26-10. The Spacing Modifier Letters block of UnicodeCombining Diacritical MarksThe Combining Diacritical Marks block contains characters that are not used on their own, such as the accent grave and circumflex. Instead, they are merged with the preceding character to form a single glyph. For example, to write the character Ñ, you could type the ASCII letter N followed by the combining tilde character, like this: Figure 26-11. The Combining Diacritical Marks block of UnicodeGreek and CopticThe Greek block of Unicode is used primarily for the modern Greek language. Currently, it's the only option for the Greek-derived Coptic script, but it doesn't really serve that purpose very well, and a separate Coptic block is a likely addition in the future. Extending coverage to classical and Byzantine Greek requires many more accented characters, which are available in the Greek Extended Block, shown in Figure 26-22, or by combining these characters with the Combining Diacritical Marks in Figure 26-11. The Greek alphabet is also a fertile source of mathematical and scientific notation, though some common letters, such as Figure 26-12. The Greek and Coptic block of UnicodeCyrillicWhile the Cyrillic script shown in Figure 26-13 is most familiar to Western readers from its use for Russian, it's also used for other Slavic languages, including Serbian, Ukrainian, and Byelorussian, and for many non-Slavic languages of the former Soviet Union, such as Azerbaijani, Tuvan, and Ossetian. Indeed, many characters in this block are not actually found in Russian, but exist only in other languages written in the Cyrillic script. Following the breakup of the Soviet Union, some non-Slavic languages, such as Moldavian and Azerbaijani, are now reverting to Latin-derived scripts. Figure 26-13. The Cyrillic block of UnicodeArmenian The Armenian script shown in Figure 26-14 is used for writing the Armenian language, currently spoken by about seven million people around the world. Figure 26-14. The Armenian block of UnicodeHebrewThe Hebrew alphabet is used for Hebrew, Yiddish, and Judezmo. It's also occasionally used for mathematical notation. See Figure 26-15. Figure 26-15. The Hebrew block of UnicodeArabicThe Arabic script shown in Figure 26-16 is used for many languages besides Arabic, including Kurdish, Pashto, Persian, Sindhi, and Urdu. Turkish was also written in the Arabic script until early in the twentieth century when Turkey converted to a modified Latin alphabet. Figure 26-16. The Arabic block of UnicodeDevanagariThe Devanagari script is used for many languages of the Indian subcontinent, including Awadhi, Bagheli, Bhatneri, Bhili, Bihari, Braj Bhasa, Chhattisgarhi, Garhwali, Gondi, Harauti, Hindi, Ho, Jaipuri, Kachchhi, Kanauji, Konkani, Kului, Kumaoni, Kurku, Kurukh, Marwari, Mundari, Newari, Palpa, and Santali. It's also used for the classical language Sanskrit. See Figure 26-17. Figure 26-17. The Devanagari block of UnicodeThaiThe Thai script is used for Thai and other Southeast Asian languages, including Kuy, Lavna, and Pali. See Figure 26-18. Figure 26-18. The Thai block of UnicodeTibetanThe Tibetan script is used to write the various dialects of Tibetan and Dzongkha, Bhutan's main language. Like Chinese, Tibetan is divided into mutually unintelligible spoken languages, though the written forms are identical. See Figure 26-19. Figure 26-19. The Tibetan block of UnicodeEthiopicThe Ethiopic script is used by several languages in Ethiopia, including Amharic. Tigre, Oromo, and the liturgical language Ge'ez. See Figure 26-20. Figure 26-20. The Ethiopic block of UnicodeLatin Extended AdditionalThe Latin Extended Additional characters are single code-point representations of letters combined with diacritical marks. This block is particularly useful for modern Vietnamese. See Figure 26-21. Figure 26-21. The Latin Extended Additional block of UnicodeGreek ExtendedThe Greek Extended block shown in Figure 26-22 contains mostly archaic letters and accented letters that are used in classical and Byzantine Greek, but not in modern Greek. Figure 26-22. The Greek Extended block of UnicodeGeneral Punctuation The General Punctuation block shown in Figure 26-23 contains punctuation characters used across a variety of languages and scripts that are not already encoded in Latin-1. Characters 0x2000 through 0x200B are all varying amounts of whitespace ranging from zero width (0x200B) to six ems (0x2007). 0x200C through 0x200F and 0x206A through 0x206F are nonprinting format characters with no graphical representation. Figure 26-23. The General Punctuation block of UnicodeCurrency SymbolsThe Currency Symbols block includes a few monetary symbols not already encoded in other blocks, such as the Indian rupee, the Italian lira, and the Greek drachma. See Figure 26-24. Figure 26-24. The Currency Symbols block of UnicodeLetter-Like SymbolsThe Letter-Like Symbols block covers characters that look like letters, but really aren't, such as the Figure 26-25. The Letter-Like Symbols block of UnicodeArrowsThe Arrows block contains commonly needed arrow characters, as shown in Figure 26-26. Figure 26-26. The Arrows block of UnicodeMathematical OperatorsThe Mathematical Operators block shown in Figure 26-27 contains a wide variety of symbols used in higher mathematics. A few of these symbols superficially resemble letters in other blocks. For instance, in most fonts character 2206, Figure 26-27. The Mathematical Operators block of UnicodeUnicode 3.1.1 adds one more block of mathematical alphanumeric symbols in Plane 1 between 0x1D400 and 0x1D7FF as shown in Figure 26-28. Mostly these are repetitions of the ASCII and Greek letters and digits in what would normally be considered font variations. For instance, 0x1D400 is mathematical bold capital A. The justification for these is that when used in an equation, they really aren't the same characters as the equivalent glyphs in text. Figure 26-28. The Mathematical Alphanumeric Symbols block of UnicodeMiscellaneous TechnicalThe Miscellaneous Technical block shown in Figure 26-29 contains an assortment of symbols taken from electronics, quantum mechanics, the APL developing language, the ISO-9995-7 standard for language-neutral keyboard pictograms, and other sources. Figure 26-29. The Miscellaneous Technical block of UnicodeOptical Character RecognitionThe Optical Character Recognition (OCR) block shown in Figure 26-30 includes the OCR-A characters that are not already encoded as ASCII and magnetic-ink character-recognition symbols used on checks. Figure 26-30. The Optical Character Recognition block of UnicodeGeometric ShapesThe Geometric Shapes block combines simple triangles, squares, circles, and other shapes found in various characters sets Unicode attempts to superset. See Figure 26-31. Figure 26-31. The Geometric Shapes block of UnicodeMiscellaneous SymbolsThe Miscellaneous Symbols block contains mostly pictographic symbols found in vendor and national character sets that preceded Unicode. See Figure 26-32. Figure 26-32. The Miscellaneous Symbols block of UnicodeDingbatsThe Dingbats block shown in Figure 26-33 is based on characters in the popular Adobe Zapf Dingbats font. Figure 26-33. The Dingbats block of Unicode |

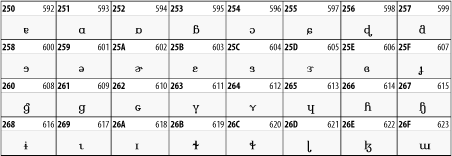


 (Unicode code point
(Unicode code point 
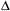 and
and 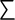 , are encoded separately in the Mathematical Operators block in
, are encoded separately in the Mathematical Operators block in 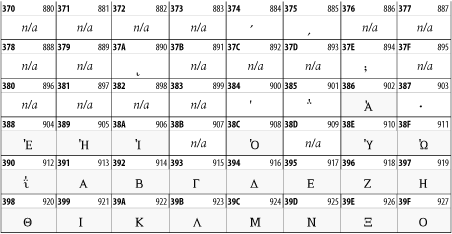


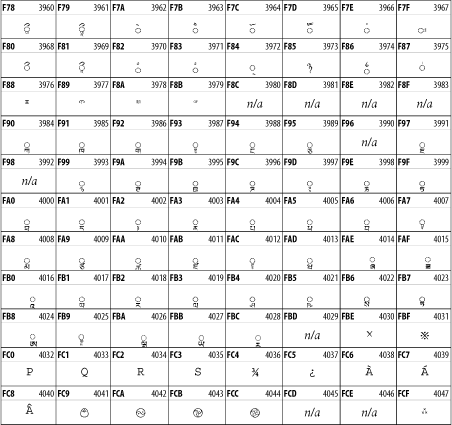



 symbol used to represent a prescription. See
symbol used to represent a prescription. See