Client Configuration in Depth
ssh and scp take their cues from command-line options, configuration-file keywords, and environment variables. SSH1, SSH2, and OpenSSH clients behave differently and obey different settings, but as usual, we cover them simultaneously. When a setting is supported by only some of these products, we'll say so.
Remote Account Name
ssh and scp assume that your local and remote usernames are the same. If your local username is henry and you run:
# SSH1, SSH2, OpenSSH $ ssh server.example.com
ssh will assume your remote username is also henry and requests a connection to that account on server.example.com. If your remote account name differs from the local one, you must tell the SSH client your remote account name. For henry to connect to a remote account called sally, he can use the -l command-line option:
# SSH1, SSH2, OpenSSH $ ssh -l sally server.example.com
If copying files with
scp, the syntax is different for specifying the remote account name, looking more like an email address. ["Full Syntax"] To copy the file myfile to the remote account sally on server.example.com:
# SSH1, SSH2, OpenSSH $ scp myfile sally@server.example.com:
If you frequently connect to a remote machine using a different username, instead of monkeying with command-line options, specify the remote username in your client configuration file. The
User keyword serves this purpose, and both ssh and scp pay attention to it. The following table shows how to declare that your remote username is sally on a given remote host:
| SSH1, OpenSSH | SSH2 |
|---|---|
Host server.example.com User sally |
server.example.com: User sally |
Now, when connecting to server.example.com, you don't have to specify that your remote username is sally:
# The remote username sally will be used automatically $ ssh server.example.com
Tricks with remote account names
WithUser and nicknames, you can significantly shorten the command lines you type for ssh and scp. Continuing the preceding example with "sally", if you have the configuration shown in this table:
| SSH1, OpenSSH | SSH2 |
|---|---|
Host simple HostName server.example.com User sally |
simple: Host server.example.com User sally |
then these long commands:
$ ssh server.example.com -l sally $ scp myfile sally@server.example.com:
may be reduced to:
$ ssh simple $ scp myfile simple:
This table shows how you can specify separately several different accounts names on different hosts, each in its own section of the configuration file:
| SSH1, OpenSSH | SSH2 |
|---|---|
Host server.example.com User sally ... Host another.example.com User sharon ... |
server.example.com: User sally ... another.example.com: User sharon ... |
This technique is convenient if you have only one account on each remote machine. But suppose you have two accounts on server.example.com, called sally and sally2. Is there some way to specify both in the configuration file? The following attempt doesn't work (we show SSH1 syntax only):
# THIS WILL NOT WORK PROPERLY Host server.example.com User sally User sally2 Compression yes
because only the first value (sally) prevails. To get around this limitation, you can use nicknames to create two sections for the same machine in your configuration file, each with a different
User:
# SSH1, OpenSSH # Section 1: Convenient access to the sally account Host sally-account HostName server.example.com User sally Compression yes # Section 2: Convenient access to the sally2 account Host sally2-account HostName server.example.com User sally2 Compression yes
Now you can access the two accounts easily by nickname:
$ ssh sally-account $ ssh sally2-account
This works, but it isn't ideal. You've duplicated your settings (
HostName and Compression) in each section. Duplication makes a configuration file harder to maintain, since any future changes needs to be applied twice. (In general, duplication isn't good software engineering.) Are you doomed to duplicate? No, there's a better solution. Immediately after the two sections, create a third section with a Host wildcard that matches both sally-account and sally2-account. Suppose you use sally*-account and move all duplicated settings into this new section:
# SSH1, OpenSSH Host sally*-account HostName server.example.com Compression yes
The end result is shown in this table:
| SSH1, OpenSSH | SSH2 |
|---|---|
Host sally-account User sally Host sally2-account User sally2 Host sally*-account HostName server.example.com Compression yes |
sally-account: User sally sally2-account: User sally2 sally*-account: Host server.example.com Compression yes |
Since sally*-account matches both previous sections, its full name and compression settings apply to both sally-account and sally2-account. Any settings that differ between sally-account and sally2-account (in this case, User) are kept in their respective sections. You've now achieved the same effect as in the previous example -- two accounts with different settings on the same remote machine -- but with no duplication of settings.
User Identity
SSH identifies you by anidentity represented by a key pair (SSH-1) or a collection of key pairs (SSH-2). ["What Is an Identity?"] Normally, SSH clients use your default key file (SSH1, OpenSSH) or default identification file (SSH2) to establish an authenticated connection. However, if you've created other keys, you may instruct SSH clients to use them to establish your identity. A command-line option (-i ) and configuration keyword (IdentityFile) are available for this purpose.In SSH1 and OpenSSH, for example, if you have a private key file called my-key, you can make clients use it with the commands:
$ ssh1 -i my-key server.example.com $ scp1 -i my-key myfile server.example.com:
or with the configuration keyword:
IdentityFile my-key
The file location is assumed to be relative to the current directory, i.e., in these cases the file is /my-key.SSH2 also has -i and
IdentityFile, but their use is slightly different. Instead of a key file, you supply the name of an identification file:[93]
[93]In SSH2 2.0.13 and earlier, the -i option and IdentityFile require the identity file to be in your SSH2 directory, ~/.ssh2. SSH2 2.1.0 and later accept absolute pathnames; any path that doesn't begin with a slash ( /) is treated as relative to ~/.ssh2.
$ ssh2 -i my-id-file server.example.com IdentityFile my-id-file
Take note of this difference between
ssh1 and ssh2. If you mistakenly provide a key filename to ssh2, the client attempts to read the key file as if it's an identification file, sending a random result to the SSH2 server. Authentication mysteriously fails, possibly with the log message "No further authentication methods available," or you may be prompted for your login password rather than your public key passphrase.Multiple identities can be quite useful. ["Multiple Identities"] For example, you can set up your remote account to run specific programs when a second key is used. The ordinary command:
$ ssh server.example.com
initiates a regular login session, but:
$ ssh -i other_identity server.example.com
can run a complex batch process on server.example.com. Using configuration keywords, you can accomplish the same effect by specifying an alternative identity as shown in this table:
| SSH1, OpenSSH | SSH2 |
|---|---|
Host SomeComplexAction HostName server.example.com IdentityFile other_identity ... |
SomeComplexAction: Host server.example.com IdentityFile other_identity ... |
You can then invoke:
$ ssh SomeComplexAction
SSH1 and OpenSSH can specify multiple identities in a single command:[94]
[94]SSH2 accomplishes the same thing with identification files, which may contain multiple keys.
# SSH1, OpenSSH $ ssh -i id1 -i id2 -i id3 server.example.com
or:
# SSH1, OpenSSH Host server.example.com IdentityFile id1 IdentityFile id2 IdentityFile id3
Multiple identities are tried in order until one successfully authenticates. However, SSH1 and OpenSSH limit you to 100 identities per command.If you plan to use multiple identities frequently, remember that an SSH agent can eliminate hassle. Simply load each identity's key into the agent using
ssh-add, and you won't have to remember multiple passphrases while you work.
Host Keys and Known-Hosts Databases
Every SSH server has a host key ["The Architecture of an SSH System"] that uniquely identifies the server to clients. This key helps prevent spoofing attacks. When an SSH client requests a connection and receives the server's host key, the client checks it against a local database of known host keys. If the keys match, the connection proceeds. If they don't, the client behaves according to several options you can control.In SSH1 and OpenSSH, the host key database is maintained partly in a serverwide location (/etc/ssh_known_hosts) and partly in the user's SSH directory (~/.ssh/known_hosts).[95] In SSH2, there are two databases of host keys for authenticating server hosts (the "hostkeys" map in /etc/ssh2/hostkeys) and client hosts (the "knownhosts" map); in this section we are concerned only with the former. Similar to its SSH1 counterpart, the SSH2 hostkeys map is maintained in a serverwide directory (/etc/ssh2/hostkeys/ ) and a per-account directory (~/.ssh2/hostkeys/ ). In this section, we refer to the SSH1, SSH2, and OpenSSH map simply as thehost key database.
[95]OpenSSH additionally keeps SSH-2 known host keys in the file ~/.ssh/known_hosts2.
Strict host key checking
Suppose you request an SSH connection with server.example.com, which sends its host key in response. Your client looks up server.example.com in its host key database. Ideally, a match is found and the connection proceeds. But what if this doesn't happen? Two scenarios may arise:- SCENARIO 1
- A host key is found for server.example.com in the database, but it doesn't match the incoming key. This can indicate a security hazard, or it can mean that server.example.com has changed its host key, which can happen legitimately. ["Man-in-the-Middle Attacks"]
- SCENARIO 2
- No host key for server.example.com exists in the database. In this case, the SSH client is encountering server.example.com for the first time.
StrictHostKeyChecking, which may have three values:
yes- Be strict. If a key is unknown or has changed, the connection fails. This is the most secure value, but it can be inconvenient or annoying if you connect to new hosts regularly, or if your remote host keys change frequently.
no- Not strict. If a key is unknown, automatically add it to the user's database and proceed. If a key has changed, leave the known hosts entry intact, print a warning, and permit the connection to proceed. This is the least secure value.
ask- Prompt the user. If a key is unknown, ask whether it should be added to the user's database and whether to connect. If a key has changed, ask whether to connect. This is the default and a sensible value for knowledgeable users. (Less experienced users might not understand what they're being asked and therefore may make the wrong decision.)
# SSH1, SSH2, OpenSSH StrictHostKeyChecking yes
Table 7-1 summarizes SSH's
StrictHostKeyChecking's behavior.
Table 7-1. StrictHostKeyChecking Behavior
| Key Found? | Match? | Strict? | Action |
|---|---|---|---|
| Yes | Yes | - | Connect |
| Yes | No | Yes | Warn and fail |
| Yes | No | No | Warn and connect |
| Yes | No | Ask | Warn and ask whether to connect |
| No | - | Yes | Warn and fail |
| No | - | No | Add key and connect |
| No | - | Ask | Ask whether to add key and to connect |
OpenSSH has an additional keyword, CheckHostIP, to make a client verify the IP address of an SSH server in the database. Its values may be yes (the default, to verify the address) or no. The value yes provides security against name service spoofing attacks. ["Name Service and IP Spoofing"]
# OpenSSH only CheckHostIP no
Moving the known hosts files
SSH1 and OpenSSH permit the locations of the host key database, both the serverwide and per-account parts, to be changed using configuration keywords.GlobalKnownHostsFile defines an alternative location for the serverwide file. It doesn't actually move the file -- only the system administrator can do that -- but it does force your clients to use another file in its place. This keyword is useful if the file is outdated, and you want your clients to ignore the serverwide file, particularly if you're tired of seeing warning messages from your clients about changed keys.
# SSH1, OpenSSH GlobalKnownHostsFile /users/smith/.ssh/my_global_hosts_file
Similarly, you can change the location of your per-user part of the database with the keyword
UserKnownHostsFile:
# SSH1, OpenSSH UserKnownHostsFile /users/smith/.ssh/my_local_hosts_file
TCP/IP Settings
SSH uses TCP/IP as its transport mechanism. Most times you don't need to change the default TCP settings, but in such situations as the following, it's necessary:- Connecting to SSH servers on other TCP ports
- Using privileged versus nonprivileged ports
- Keeping an idle connection open by sending keepalive messages
- Enabling the Nagle Algorithm (TCP_NODELAY)
- Requiring IP addresses to be Version 4 or 6
Selecting a remote port
Most SSH servers listen on TCP port 22, so clients connect to this port by default. Nevertheless, sometimes you need to connect to an SSH server on a different port number. For example, if you are a system administrator testing a new SSH server, you can run it on a different port to avoid interference with an existing server. Then your clients need to connect to this alternate port. This can be done with the client'sPort keyword, followed by a port number:
# SSH1, SSH2, OpenSSH Port 2035
or the -p command-line option followed by the port number:
# SSH1, SSH2, OpenSSH $ ssh -p 2035 server.example.com
You can also specify an alternative port for
scp, but the command-line option is -P instead of -p:[96]
[96]scpalso has a -p option with the same meaning as forrcp: "preserve file permissions."
# SSH1, SSH2, OpenSSH $ scp -P 2035 myfile server.example.com:
In SSH2 2.1.0 and later, you can also provide a port number as part of the user and host specification, preceded by a hash sign. For example, the commands:
# SSH2 only $ ssh2 server.example.com#2035 $ ssh2 smith@server.example.com#2035 $ scp2 smith@server.example.com#2035:myfile localfile
each create SSH-2 connections to remote port 2035. (We don't see much use for this alternative syntax, but it's available.)After connecting to the server,
ssh sets an environment variable in the remote shell to hold the port information. For SSH1 and OpenSSH, the variable is called SSH_CLIENT, and for SSH2 it is SSH2_CLIENT. The variable contains a string with three values, separated by a space character: the client's IP address, the client's TCP port, and the server's TCP port. For example, if your client originates from port 1016 on IP address 24.128.23.102, connecting to the server's port 22, the value is:
# SSH1, OpenSSH $ echo $SSH_CLIENT 24.128.23.102 1016 22 # SSH2 only $ echo $SSH2_CLIENT 24.128.23.102 1016 22
These variables are useful for scripting. In your shell's startup file (e.g., ~/.profile, ~/.login), you can test for the variable, and if it exists, take actions. For example:
#!/bin/sh # Test for an SSH_CLIENT value of nonzero length if [ -n "$SSH_CLIENT" ] then # We logged in via SSH. echo 'Welcome, SSH-1 user!' # Extract the IP address from SSH_CLIENT IP=`echo $SSH_CLIENT | awk '{print $1}'` # Translate it to a hostname. HOSTNAME=`host $IP | grep Name: | awk '{print $2}'` echo "I see you are connecting from $HOSTNAME." else # We logged in not by SSH, but by some other means. echo 'Welcome, O clueless one. Feeling insecure today?' fi
Forcing a nonprivileged local port
SSH connections get locally bound to a privileged TCP port, one whose port number is below 1024. ["Trusted-host authentication (Rhosts and RhostsRSA)"] If you ever need to override this feature -- say, if your connection must pass through a firewall that doesn't permit privileged source ports -- use the -P command-line option:# SSH1, SSH2, OpenSSH $ ssh -P server.example.com
The -P option makes
ssh select a local port that is nonprivileged.[97] Let's watch this work by printing the value of SSH_CLIENT on the remote machine, with and without -P. Recall that SSH_CLIENT lists the client IP address, client port, and server port, in order.
[97]Yes, it's counterintuitive for -P to mean nonprivileged, but that's life.
# Default: bind to privileged port. $ ssh server.example.com 'echo $SSH_CLIENT' 128.119.240.87 1022 22 < 1024
# Bind to non-privileged port. $ ssh -P server.example.com 'echo $SSH_CLIENT' 128.119.240.87 36885 22 >= 1024
The configuration keyword
UsePrivilegedPort (SSH1, OpenSSH) has the same function as -P, with values yes (use a privileged port, the default) and no (use a nonprivileged port):
# SSH1, OpenSSH UsePrivilegedPort no
scp also permits binding to nonprivileged ports with these configuration keywords. However, the command-line options are different from those of ssh. For scp1, the option -L means to bind to a nonprivileged port, the same as setting UsePrivilegedPort to no:[98]
[98]The -P option was already taken for setting the port number. The source code suggests that -L can mean "large local port numbers."
# SSH1 only $ scp1 -L myfile server.example.com:
scp2 has no command-line option for this feature.For trusted-host authentication you must use a privileged port. In other words, if you use -P or UsePrivilegedPort no, you disable Rhosts and RhostsRSA authentication. ["Trusted-host authentication (Rhosts and RhostsRSA)"]
Keepalive messages
TheKeepAlive keyword instructs the client how to proceed if a connection problem occurs, such as a prolonged network outage or a server machine crash:
# SSH1, SSH2, OpenSSH KeepAlive yes
The value
yes (the default) tells the client to transmit and expect periodic keepalive messages. If the client detects a lack of responses to these messages, it shuts down the connection. The value no means not to use keepalive messages.Keepalive messages represent a tradeoff. If they are enabled, a faulty connection is shut down, even if the problem is transient. However, the TCP keepalive timeout on which this feature is based is typically several hours, so this shouldn't be a big problem. If keepalive messages are disabled, an unused faulty connection can persist indefinitely.KeepAlive is generally more useful in the SSH server, since a user sitting on the client side will certainly notice if the connection becomes unresponsive. However, SSH can connect two programs together, with the one running the SSH client waiting for input from the other side. In such a situation, it can be necessary to have a dead connection be eventually detected.KeepAlive isn't intended to deal with the problem of SSH sessions being torn down because of firewall, proxying, NAT, or IP masquerading timeouts. ["KeepAlive"]
Controlling TCP_NODELAY
TCP/IP has a feature called the Nagle Algorithm, an optimization for reducing the number of TCP segments sent with very small amounts of data. ["TCP/IP support"] SSH2 clients may also enable or disable the Nagle Algorithm using theNoDelay keyword:
# SSH2 only NoDelay yes
Legal values are
yes (to disable the algorithm) and no (to enable it; the default).
Requiring IPv4 and IPv6
OpenSSH can force its clients to use Internet Protocol Version 4 (IPv4) or 6 (IPv6) addresses. IPv4 is the current version of IP used on the Internet; IPv6 is the future, permitting far more addresses than IPv4 can support. For more information on these address formats visit:http://www.ipv6.orgTo force IPv4 addressing, use the -4 flag:
# OpenSSH only $ ssh -4 server.example.com
or likewise for IPv6, use -6 :
# OpenSSH only $ ssh -6 server.example.com
Making Connections
Under the best conditions, an SSH client attempts a secure connection, succeeds, obtains your authentication credentials, and executes whatever command you've requested, be it a shell or otherwise. Various steps in this process are configurable, including:- The number of times the client attempts the connection
- The look and behavior of the password prompt (for password authentication only)
- Suppressing all prompting
- Running remote commands interactively with a tty
- Running remote commands in the background
- Whether or not to fall back to an insecure connection, if a secure one can't be established
- The escape character for interrupting and resuming an SSH session
Number of connection attempts
If you run an SSH1 or OpenSSH client and it can't establish a secure connection, it will retry. By default, it tries four times in rapid succession. You can change this behavior with the keywordConnectionAttempts:
# SSH1, OpenSSH ConnectionAttempts 10
In this example,
ssh1 tries 10 times before admitting defeat, after which it either quits or falls back to an insecure connection. We'll come back to this when we discuss the keyword FallBackToRsh. ["RSH issues"]Most people don't have much use for this keyword, but it might be helpful if your network is unreliable. Just for fun, you can force ssh1 to give up immediately by setting ConnectionAttempts equal to zero:
# SSH1, OpenSSH $ ssh -o ConnectionAttempts=0 server.example.com Secure connection to server.example.com refused.
Password prompting in SSH1
If you're using password authentication in SSH1, clients prompt like this for your password:smith@server.example.com's password:
You may tailor the appearance of this prompt. Perhaps for privacy reasons, you might not want your username or hostname appearing on the screen. The configuration keyword
PasswordPromptLogin, with a value of yes (the default) or no, prints or suppresses the username. For example:
# SSH1 only PasswordPromptLogin no
causes this prompt to appear without the username:
server.example.com password:
Likewise,
PasswordPromptHost prints or suppresses the hostname, again with values of yes (the default) or no. The line:
# SSH1 only PasswordPromptHost no
makes the prompt appear without the hostname:
smith's password:
If both keywords have value
no, the prompt is reduced to:
Password:
Remember, this applies only to password authentication. With public-key authentication, the prompt for a passphrase is completely different and not controlled by these keywords:
Enter passphrase for RSA key 'Dave Smith's Home PC':
You may also control the number of times you are prompted for your password if mistyped. By default, you're prompted only once, and if you mistype the password, the client exits. The keyword
NumberOfPasswordPrompts may change this to between one and five prompts:[99]
[99]The upper limit of five prompts is enforced by the SSH server.
# SSH1, OpenSSH NumberOfPasswordPrompts 3
Now your SSH clients provides three chances to type your password correctly.
Password prompting in SSH2
SSH2 adds flexibility to password prompting. Instead of preset prompt strings, you can design your own with thePasswordPrompt keyword:
# SSH2 only PasswordPrompt Enter your password right now, infidel:
You can insert the remote username or hostname with the symbols
%U (remote username) or %H (remote hostname). For example, to emulate the SSH1 prompt:
# SSH2 only PasswordPrompt "%U@%H's password:"
Or you can be fancier:
# SSH2 only PasswordPrompt "Welcome %U! Please enter your %H password:"
Batch mode: suppressing prompts
In some cases, you don't want to be prompted for your password or RSA passphrase. Ifssh is invoked by an unattended shell script, for example, nobody will be at the keyboard to type a password. This is why SSH batch mode exists. In batch mode, all prompting for authentication credentials is suppressed. The keyword BatchMode can have a value of yes (disable prompting) or no (the default, with prompting enabled):
# SSH1, SSH2, OpenSSH BatchMode yes
Batch mode may enabled for
scp also with the -B option:
# SSH1, SSH2, OpenSSH $ scp1 -B myfile server.example.com:
Batch mode doesn't replace authentication. If a password or passphrase is required, you can't magically log in without it by suppressing the prompt. If you try, your client exits with an error message such as "permission denied." In order for batch mode to work, you must arrange for authentication to work without a password/passphrase, say, with trusted-host authentication or an SSH agent. ["Unattended SSH: Batch or cron Jobs"]
Pseudo-terminal allocation (TTY/PTY/PTTY)
A Unix tty (pronounced as it's spelled, T-T-Y) is a software abstraction representing a computer terminal, originally an abbreviation for "teletype." As part of an interactive session with a Unix machine, a tty is allocated to process keyboard input, limit screen output to a given number of rows and columns, and handle other terminal-related activities. Since most terminal-like connections don't involve an actual hardware terminal, but rather a window, a software construct called a pseudo-tty (or pty, pronounced P-T-Y) handles this sort of connection.When a client requests an SSH connection, the server doesn't necessarily allocate a pty for the client. It does so, of course, if the client requests an interactive terminal session, e.g., justssh host. But if you ask ssh to run a simple command on a remote server, such as ls :
$ ssh remote.server.com /bin/ls
no interactive terminal session is needed, just a quick dump of the output of
ls. In fact, by default sshd doesn't allocate a pty for such a command. On the other hand, if you try running an interactive command like the text editor Emacs in this manner, you get an error message:
$ ssh remote.server.com emacs -nw emacs: standard input is not a tty
because Emacs is a screen-based program intended for a terminal. In such cases, you can request that SSH allocate a pty using the -t option:
# SSH1, SSH2, OpenSSH $ ssh -t server.example.com emacs
SSH2 also has the keyword
ForcePTTYAllocation, which does the same thing as -t .[100]
[100]In SSH1 and OpenSSH, the no-pty option in authorized_keys can override this request for a tty. ["Disabling TTY Allocation"]If SSH allocates a pty, it also automatically defines an environment variable in the remote shell. The variable is SSH_TTY (for SSH1 and OpenSSH) or SSH2_TTY (for SSH2) and contains name of the character device file connected to the "slave" side of the pty, the side that emulates a real tty. We can see this in action with a few simple commands. Try printing the value of SSH_TTY on a remote machine. If no tty is allocated, the result is blank:
$ ssh1 server.example.com 'echo $SSH_TTY' [no output]
If you force allocation, the result is the name of the tty:
$ ssh1 -t server.example.com 'echo $SSH_TTY' /dev/pts/1
Thanks to this variable, you can run shell scripts on the remote machine that use this information. For example, here's a script that runs your default editor only if a terminal is available:
#!/bin/sh if [ -n $SSH_TTY -o -n $SSH2_TTY ]; then echo 'Success!' exec $EDITOR else echo "Sorry, interactive commands require a tty" fi
Place this script in your remote account, calling it
myscript (or whatever), and run:
$ ssh server.example.com myscript Sorry, interactive commands require a tty $ ssh -t server.example.com myscript Success! Emacs runs...
Backgrounding a remote command
If you try running an SSH remote command in the background, you might be surprised by the result. After the remote command runs to completion, the client automatically suspends before the output is printed:$ ssh server.example.com ls & [1] 11910 $ time passes ... [1] + Stopped (SIGTTIN) ssh server.example.com ls &
This happens because
ssh is attempting to read from standard input while in the background, which causes the shell to suspend ssh. To see the resulting output, you must bring ssh into the foreground:
$ fg README myfile myfile2
ssh provides the -n command-line option to get around this problem. It redirects standard input to come from /dev/null, which prevents ssh from blocking for input. Now when the remote command finishes, the output is printed immediately:
# SSH1, SSH2, OpenSSH $ ssh -n server.example.com ls & [1] 11912 $ time passes ... README myfile myfile2
SSH2 has a keyword
DontReadStdin that does the same thing as -n, accepting the values yes or no (the default is no):
# SSH2 only DontReadStdin yes
Backgrounding a remote command, take two
The preceding section assumed you didn't need to type a password or passphrase, e.g., that you're running an SSH agent. What happens if you use -n orDontReadStdin but the SSH client needs to read a password or passphrase from you?
$ ssh -n server.example.com ls & $ Enter passphrase for RSA key 'smith@client':
WARNING: STOP! Don't type your passphrase! Because the command is run in the background with -n, the prompt is also printed in the background. If you respond, you will be typing to the shell, not the ssh prompt, and anything you type will be visible.You need a solution that not only disables input and sends the process into the background, but also permits ssh to prompt you. This is the purpose of the -f command-line option, which instructs ssh to do the following in order:
- Perform authentication, including any prompting
- Cause the process to read from /dev/null, exactly like -n
- Put the process into the background: no "&" is needed
$ ssh -f server.example.com ls Enter passphrase for RSA key 'smith@client':********$ time passes... README myfile myfile2
SSH2 has a keyword
GoBackground that does the same thing, accepting the values yes or no (the default):
# SSH2 only GoBackground yes
GoBackground and -f also set up any port forwardings you may have specified on the command line. ["Port Forwarding Without a Remote Login"] The setup occurs after authentication but before backgrounding.
RSH issues
Suppose a remote host isn't running an SSH server, but you try to log into it via SSH. What happens? Depending on your client configuration settings, three scenarios can occur:- Scenario 1
sshattempts an SSH connection, fails, and then attempts an insecurershconnection.[101] This is the default behavior, and it's a sensible guess of what a user might have done anyway. ("Hmm, I can't connect by SSH. I'll tryrshinstead.") The connection attempt displays:[101]Only if
sshis compiled with support forrsh, using the compile-time flag--with-rsh. ["R-commands (rsh) compatibility"] If not, Scenario 2, fail and stop, is the only possibility.
$ ssh no-ssh-server.com Secure connection to no-ssh-server.com on port 22 refused; reverting to insecure method. Using rsh. WARNING: Connection will not be encrypted.
- Scenario 2
sshattempts an SSH connection, fails, and stops. This behavior is best for security-conscious installations wherershis simply not acceptable.
$ ssh no-ssh-server.com Secure connection to no-ssh-server.com on port 22 refused.
- Scenario 3
- Rather than attempt an SSH connection at all,
sshimmediately attempts an insecurershconnection.[102] This is best if you know in advance that certain machines don't run SSH servers, and you findrshacceptable.[102]Again, only if
sshis compiled with-- with-rsh.
$ ssh no-ssh-server.com Using rsh. WARNING: Connection will not be encrypted.
FallBackToRsh controls what happens when an SSH connection attempt fails: should it then try an rsh connection or not? FallBackToRsh may have the value yes (the default, to try rsh) or no (don't try rsh):
# SSH1, SSH2, OpenSSH FallBackToRsh no
The keyword
UseRsh instructs ssh to use rsh immediately, not even attempting an SSH connection. Permissible values are yes (to use rsh) and no (the default, to use ssh):
# SSH1, SSH2, OpenSSH UseRsh yes
Therefore, here is how to create these three scenarios:.
- Scenario 1: Try
sshfirst, then fall back torsh -
# SSH1, SSH2, OpenSSH FallBackToRsh yes UseRsh no
- Scenario 2: Use ssh only
-
# SSH1, SSH2, OpenSSH FallBackToRsh no UseRsh no
- Scenario 3: Use
rshonly -
# SSH1, SSH2, OpenSSH UseRsh yes
UseRsh keyword. Make sure to limit its effects to individual remote hosts in your configuration file, not to all hosts. The following table depicts an example that can disable encryption for all your SSH connections:
| SSH1, OpenSSH | SSH2 |
|---|---|
# Never do this! Security risk!! Host * UseRsh yes |
# Never do this! Security risk!! *: UseRsh yes |
Escaping
Recall that thessh client has an escape sequence feature. ["The Escape Character"] By typing a particular character, normally a tilde (~), immediately after a newline or carriage return, you can send special commands to ssh: terminate the connection, suspend the connection, and so forth. But sometimes the default escape character can cause a problem.Suppose you connect by ssh from host A to host B, then from host B to host C, and finally from host C to host D, making a chain of ssh connections. (We represent the machines' shell prompts as A$, B$, C$, and D$.)
A$ ssh B ... B$ ssh C ... C$ ssh D ... D$
While logged onto host D, you press the Return key, then
~ ^Z (tilde followed by Control-Z) to suspend the connection temporarily. Well, you've got three ssh connections active, so which one gets suspended? The first one does, and this escape sequence brings you back to the host A prompt. Well, what if you want to escape back to host B or C ? There are two methods, one with forethought and one on the spur of the moment.If you prepare in advance, you may change the escape character for each connection with the configuration keyword EscapeChar, followed by a character:
# SSH1, SSH2, OpenSSH EscapeChar %
or the -e command-line option, followed again by the desired character (quoted if necessary to protect it from expansion by the shell):
# SSH1, SSH2, OpenSSH $ ssh -e '%' server.example.com
So, going back to our example of hosts A through D, you want a different escape character for each segment of this chain of connections. For example,
# SSH1, SSH2, OpenSSH A$ ssh B ... B$ ssh -e '$' C ... C$ ssh -e '%' D ... D$
Now, while logged onto host D, a tilde still brings you back to host A, but a dollar sign brings you back to host B, and a percent sign back to host C. The same effect can be achieved with the
EscapeChar keyword, but the following table shows that more forethought is required to set up configuration files on three hosts.
| SSH1, OpenSSH | SSH2 |
|---|---|
# Host A configuration file Host B EscapeChar ~ # Host B configuration file Host C EscapeChar ^ # Host C configuration file Host D EscapeChar % |
# Host A configuration file B: EscapeChar ~ # Host B configuration file C: EscapeChar ^ # Host C configuration file D: EscapeChar % |
Even if you don't normally make chains of SSH connections, you might still want to change the escape character. For example, your work might require you to type a lot of tildes for other reasons, and you might accidentally type an escape sequence such as ~. (tilde period) and disconnect your session. Oops!The second method requires no forethought. Recall that typing the escape character twice sends it literally across the SSH connection. ["The Escape Character"] Therefore, you can suspend the second SSH connection by typing two escapes, the third by typing three escapes, and so on. Remember you must precede your escape characters by pressing the Return key. While logged onto host D, you could escape back to host B, for example, by hitting the Return key, then typing two tildes, and Control-Z.
Proxies and SOCKS
SOCKS is an application-layer network proxying system supported by various SSH implementations. Proxying in general provides a way to connect two networks at the application level, without allowing direct network-level connectivity between them. Figure 7-3 shows a typical SOCKS installation.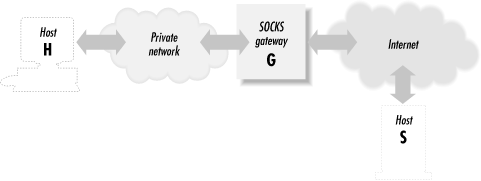
Figure 7-3. A typical SOCKS installation
The figure shows a private network and the Internet. The gateway machine is connected to both, but doesn't function as a router; there's no direct IP connectivity between the two networks. If a program running on H wants to make a TCP connection to a server on S, it instead connects to the SOCKS server running on G. Using the SOCKS protocol, H requests a connection to S. The SOCKS server makes a connection from G to S on behalf of H and then steps out of the way, passing data back and forth between H and S.A general drawback of application-level proxying is lack of transparency: only those programs written with support for the particular proxying scheme have network access. SOCKS, however, isn't specific to any higher-level protocol such as HTTP or SMTP. It provides general services: makes a TCP connection, pings a host, performs a traceroute, etc. Many of its services match the existing developing boundary between applications and network-services libraries. As a result, on modern computer systems employing dynamically linked libraries, it is often possible to extend SOCKS to non-SOCKS-aware applications, such as SSH, by replacing the right libraries with SOCKS-aware ones.SOCKS comes in two versions, SOCKS4 and SOCKS5. The major difference between them is that SOCKS5 performs user authentication, whereas SOCKS4 doesn't. With SOCKS5, you can require the client to provide a username and password (or other authentication schemes) before accessing its network services.SOCKS in SSH1
The following description assumes you've installed SSH1 with SOCKS support, using the NECsocks5 package. ["SOCKS proxy support"] If you use a different package, the SOCKS-specific configuration details may differ from those we describe.By the way, the names are a little confusing. Even though the NEC software is named "socks5," it implements both the SOCKS4 and SOCKS5 protocols. We write "socks5" in lowercase to refer to the NEC implementation.Once you've installed your SOCKS-aware ssh, you can control its SOCKS-related behavior using environment variables. By default, ssh doesn't use SOCKS at all. If you set SOCKS_SERVER to "socks.shoes.com", ssh uses the SOCKS gateway running on socks.shoes.com for any connection to an SSH server outside the local host's subnet (as defined by netmask setting on the relevant network interface). If you want ssh to use SOCKS for all connections, even local-subnet ones, set the variable SOCKS5_NONETMASKCHECK. If your SOCKS gateway requires username/password authentication, set the variables SOCKS5_USER and SOCKS5_PASSWD with your username and password. SOCKS-specific debugging output is available by setting environment variables:
#!/bin/csh setenv SOCKS5_DEBUG 3 setenv SOCKS5_LOG_STDERR
The documentation mentions debugging levels only up to 3, but in fact the code uses higher ones that are sometimes crucial to understanding a problem. Try cranking up the value if you're not getting enough information.
SOCKS in SSH2
SSH2 provides SOCKS4 support only. It is integrated into the SSH2 code, so you don't need to install a separate SOCKS package. You also don't need to enable SOCKS specifically when compiling; it is always included.The SSH2 SOCKS feature is controlled with a single parameter, set with theSocksServer configuration keyword or the SSH_SOCKS_SERVER environment variable. The configuration option overrides the environment variable if both are present.The SocksServer keyword is a string with the following format:
socks://[user]@gateway[:port]/[net1/mask1,net2/mask2,]
Here, gateway is the machine running the SOCKS server, user is the username you supply for identification to SOCKS, and port is the TCP port for the SOCKS server (by default, 1080). The net/mask entries indicate netblocks that are to be considered local; that is,
ssh2 uses SOCKS only for connections lying outside the given network ranges. The mask is given as a number of bits, not an explicit mask, i.e., 192.168.10.0/24 instead of 192.168.10.0/255.255.255.0.The parts of the string enclosed in square brackets are optional. So an SSH_SOCKS_SERVER value can be as simple as this:
socks://laces.shoes.net
With this value,
ssh2 uses SOCKS for all connections. It connects to a SOCKS server running on laces.shoes.net, port 1080, and it doesn't supply a username. You might wonder why there's a username but no password field. Recall that SOCKS4 doesn't support user authentication. The username is advisory only; the SOCKS server has no way of verifying your claimed identity.You'll probably never want to use an SSH_SOCKS_SERVER setting as simple as this one, which uses the SOCKS server for all ssh2 connections, even those connecting back to the same machine or to a machine on the same network. A better setup is to use SOCKS only for hosts on the other side of the gateway from you. Here's a more complete example:
socks://dan@laces.shoes.net:4321/127.0.0.0/8,192.168.10.0/24
With this value,
ssh2 connects directly to itself via its loopback address (127.0.0.1), or to hosts on the class C network 192.168.10.0. It uses SOCKS for all other connections, supplying the username "dan" and looking for the SOCKS server on port 4321.
SOCKS in OpenSSH
OpenSSH doesn't include explicit support for SOCKS. However, we have found that it works just fine with therunsocks program supplied with NEC's SOCKS5 package. runsocks is a wrapper that rearranges dynamic linking order so that sockets routines such as bind, connect, etc., are replaced by SOCKS-ified versions at runtime. On a Linux system, we found that setting the appropriate socks5 environment variables as discussed earlier, and then running:
% runsocks ssh ...
caused OpenSSH to work seamlessly through our SOCKS server. One caveat, though: in order to work, the OpenSSH client must not be setuid. For obvious security reasons, shared-library loaders ignore the shenanigans of
runsocks if the executable in question is setuid. And remember that setuid is required for trusted-host authentication. ["Trusted-host authentication (Rhosts and RhostsRSA)"]At one time, there was some code in OpenSSH for SOCKS support. However, it was removed and replaced by a recommendation to use the ProxyCommand feature instead. The idea is to have a little program that just takes a hostname and port number on the command line, connects to that socket via SOCKS, then acts as a pipe, passing data back and forth between the TCP connection and its standard input and output. If this program were called ssh-proxy, it can be used with OpenSSH like so:
% ssh -o 'ProxyCommand ssh-proxy %h %p' ...
This still doesn't work with SSH1 RhostsRSA authentication unless
ssh-proxy is setuid root and written to use a privileged source port. It doesn't by itself interfere with SSH2 hostbased authentication, but it has a separate problem. ["Other SOCKS issues"]We're sure such a SOCKS proxying widget must be available somewhere, but we haven't turned one up. You can't use the SOCKS-ified telnet that comes with socks5 because it isn't transparent; bytes in the binary SSH protocol stream are interpreted as Telnet escape sequences and are munged. The authors did prove the concept, though, by taking a copy of netcat (http://www.l0pht.com/~weld/netcat/), and SOCKS-ifying it by linking against the socks5 libraries. The netcat executable is named nc; using our altered version, the following worked for us, sending the SSH connection through our SOCKS gateway:
% ssh -o 'ProxyCommand nc %h %p' ...
Perhaps the OpenSSH folks will see fit to include such a utility at some point.
Other SOCKS issues
Keep in mind that an SSH connection through SOCKS appears to come from the SOCKS gateway, not from the originating client host. This causes a problem with trusted-host authentication.sshd1 uses the source IP address of the connection to look up the client's host key, so RhostsRSA authentication will fail: it expects the gateway's host key, not that of the real client. You can get around this only by giving all the clients the same host key and associating that with the gateway in the SSH server's known-hosts database. That's not such a great arrangement, since if one host key is stolen, the thief can masquerade as any user on any of the clients, not just one. But it might be acceptable in some situations.With SSH2, the problem should be gone; the SSH-2 protocol makes hostbased authentication independent of the client host address. However, SSH2 still implements it the old way, which still doesn't work through SOCKS. You might be tempted simply to disable the address/name check yourself in the source code. Don't do it. The issue is slightly more complicated. ["Hostbased authentication"]
Forwarding
Port forwarding and X forwarding are covered in "Port Forwarding and X Forwarding" and agent forwarding in "Key Management and Agents". We mention them here only for completeness, since forwarding can be controlled in the client configuration file and on the command line.Encryption Algorithms
When establishing a connection, an SSH client and server have a little conversation about encryption. The server says, "Hello client, here are the encryption algorithms I support." In return, the client says, "Hi there server, I'd like to choose this particular algorithm, please." Normally, they reach agreement, and the connection proceeds. If they can't agree on an encryption algorithm, the connection fails.Most users let the client and server work things out themselves. But if you like, you may instruct the client to request particular encryption algorithms in its conversation with the server. In SSH1 and OpenSSH, this is done with theCipher keyword followed by your encryption algorithm of choice:
# SSH1, OpenSSH Cipher blowfish
or the -c command-line option:
# SSH1, SSH2, OpenSSH $ ssh -c blowfish server.example.com $ scp -c blowfish myfile server.example.com:
SSH2 is almost the same, but the keyword is
Ciphers (note the final "s") and is followed by one or more encryption algorithms, separated by commas, indicating that any of these algorithms is acceptable:
# SSH2, OpenSSH/2 Ciphers blowfish,3des
SSH2 also supports the -c command-line option as previously, but it may appear multiple times to specify several acceptable ciphers:
# SSH2 only $ ssh2 -c blowfish -c 3des -c idea server.example.com $ scp2 -c blowfish -c 3des -c idea myfile server.example.com:
OpenSSH/2 permits multiple algorithms to follow a single -c, separated by commas, to achieve the same effect:
# OpenSSH/2 only $ ssh -c 3des-cbc,blowfish-cbc,arcfour server.example.com
All ciphers acceptable by a server may be specified for the client. ["Encryption Algorithms"] Check the latest SSH documentation for a current list of supported ciphers.
MAC algorithms
The -m command-line option lets you select the integrity-checking algorithm, known as the MAC (Message Authentication Code), used byssh2 : ["Hash Functions"]
# SSH2 only $ ssh2 -m hmac-sha1 server.example.com
You can specify multiple algorithms on the command line, each preceded by a separate -m option:
# SSH2 only $ ssh2 -m hmac-sha1 -m another-one server.example.com
and the SSH2 server selects one to use.
Session Rekeying
TheRekeyIntervalSeconds keyword specifies how often (in seconds) the SSH2 client performs key exchange with the server to replace the session data-encryption and integrity keys. The default is 3600 seconds (one hour), and a zero value disables rekeying:[103]
[103]Note that at press time, you must disable session rekeying in the SSH2 client if you wish to use it with the OpenSSH server, because the latter doesn't yet support session rekeying. The connection dies with an error once the rekeying interval expires. This feature will likely be implemented soon, however.
# SSH2 only RekeyIntervalSeconds 7200
Authentication
In a typical SSH setup, clients try to authenticate by the strongest methods first. If a particular method fails or isn't set up, the next one is tried, and so on. This default behavior should work fine for most needs.Nevertheless, your clients may request specific types of authentication if they need to do so. For example, you might want to use public-key authentication only, and if it fails, no other methods should be tried.Requesting an authentication technique
SSH1 and OpenSSH clients can request specific authentication methods by keyword. The syntax is the same as the server's in /etc/sshd_config. ["Authentication"] You can specify:(The latter two keywords require TIS or Kerberos support compiled in, respectively.) Any or all of these keywords may appear with the valuePasswordAuthenticationRhostsAuthenticationRhostsRSAAuthenticationRSAAuthenticationTISAuthenticationKerberosAuthentication
yes or no.For SSH2, the AllowedAuthentications keyword selects one or more authentication techniques. Again, the keyword has the same use here as for the SSH2 server. ["Authentication"]OpenSSH accepts the same keywords as SSH1 except for TISAuthentication, and it adds SkeyAuthentication for one-time passwords. ["S/Key authentication"]
The server is the boss
When a client specifies an authentication technique, this is just a request, not a requirement. For example, the configuration:PasswordAuthentication yes
informs the SSH server that you, the client, agree to participate in password authentication. It doesn't guarantee that you will authenticate by password, just that you are willing to do it if the server agrees. The server makes the decision and might still authenticate you by another method.If a client wants to require an authentication technique, it must tell the server that one, and only one, technique is acceptable. To do this, the client must deselect every other authentication technique. For example, to force password authentication in SSH1 or OpenSSH:
# SSH1, OpenSSH # This guarantees password authentication, if the server supports it. PasswordAuthentication yes RSAAuthentication no RhostsRSAAuthentication no RhostsAuthentication no KerberosAuthentication no # Add any other authentication methods, with value "no"
If the server doesn't support password authentication, however, this connection attempt will fail.SSH2 has a better system: the
AllowedAuthentications keyword, which has the same syntax and meaning as the server keyword of the same name: ["Authentication"]
# SSH2 only AllowedAuthentications password
Detecting successful authentication
SSH2 provides two keywords for reporting whether authentication is successful:AuthenticationSuccessMsg and AuthenticationNotify. Each of these causes SSH2 clients to print a message after attempting authentication.AuthenticationSuccessMsg controls the appearance of the message "Authentication successful" after authentication, which is printed on standard error. Values may be yes (the default, to display the message) or no:
$ ssh2 server.example.com Authentication successful. Last login: Sat Jun 24 2000 14:53:28 -0400 ... $ ssh2 -p221 -o 'AuthenticationSuccessMsg no' server.example.com Last login: Sat Jun 24 2000 14:53:28 -0400 ...
AuthenticationNotify, an undocumented keyword, causes ssh2 to print a different message, this time on standard output. If the authentication is successful, the message is "AUTHENTICATED YES", otherwise it's "AUTHENTICATED NO". Values may be yes (print the message) or no (the default):
$ ssh2 -q -o 'AuthenticationNotify yes' server.example.com AUTHENTICATED YES Last login: Sat Jun 24 2000 14:53:35 -0400 ...
The behavior of these two keywords differs in the following ways:
AuthenticationSuccessMsgwrites to stderr;AuthenticationNotifywrites to stdout.- The -q command-line option ["Logging and Debugging"] silences
AuthenticationSuccessMsgbut notAuthenticationNotify. This makesAuthenticationNotifybetter for scripting (for example, to find out if an authentication can succeed or not). Notice thatexitis used as a remote command so the shell terminates immediately:
#!/bin/csh # Get the AUTHENTICATION line set line = `ssh2 -q -o 'AuthenticationNotify yes' server.example.com exit` # Capture the second word set result = `echo $line | awk '{print $2}'` if ( $result == "YES" ) then ...
In fact,AuthenticationNotifyis used precisely in this manner byscp2andsftp, then these programs runssh2in the background to connect to the remote host for file transfers. They wait for the appearance of the "AUTHENTICATED YES" message to know that the connection was successful, and they can now start speaking to thesftp-server.
AuthenticationSuccessMsg provides an additional safety feature: a guarantee that authentication has occurred. Suppose you invoke ssh2 and are prompted for your passphrase:
$ ssh2 server.example.com Passphrase for key "mykey": ********
You then see, to your surprise, a second passphrase prompt:
Passphrase for key "mykey":
You might conclude that you mistyped your passphrase the first time and type it again. But what if the second prompt came not from your
ssh2 client, but from the server, which has been hacked by a evil intruder? Your passphrase has just been stolen! To counteract this potential threat, ssh2 prints "Authentication successful" after authentication, so the previous session actually looks like this:
$ ssh2 server.example.com Passphrase for key "mykey": ******** Authentication successful. Passphrase for key "mykey":
The second passphrase prompt is now revealed as a fraud.
Data Compression
SSH connections may be compressed. That is, data sent over an SSH connection may be compressed automaticallybefore it is encrypted and sent, and automatically uncompressed after it is received and decrypted. If you're running SSH software on fast, modern processors, compression is generally a win. In an informal test between two Sun SPARCstation 10 workstations connected by Ethernet, we transmitted 12 MB of text from server to client over compressed and uncompressed SSH connections. With compression enabled at an appropriate level (explained later), the transmission time was halved.To enable compression for a single session, use command-line options. Unfortunately, the implementations have incompatible syntax. For SSH1 and OpenSSH, compression is disabled by default, and the -C command-line option turns it on:# SSH1, OpenSSH: turn compression ON $ ssh1 -C server.example.com $ scp1 -C myfile server.example.com:
For SSH2, however, -C means the opposite, turning compression off:
# SSH2 only: turn compression OFF $ ssh2 -C server.example.com
and +C turns it on:
# SSH2 only: turn compression ON $ ssh2 +C server.example.com
(There is no compression option for
scp2.) To enable or disable compression for all sessions, use the Compression keyword, given a value of yes or no (the default):
# SSH1, SSH2, OpenSSH Compression yes
SSH1 and OpenSSH may also set an integer
compression level to indicate how much the data should be compressed. Higher levels mean better compression but slower performance. Levels may be from to 9 inclusive, and the default level is 6.[104] The CompressionLevel keyword modifies the level:
[104]SSH's compression functionality comes from GNU Zip, a.k.a.,gzip, a compression utility popular in the Unix world. The nineCompressionLevelvalues correspond to the nine methods supported bygzip.
# SSH1, OpenSSH CompressionLevel 2
Changing the
CompressionLevel can have a drastic effect on performance. Our earlier 12-MB test was run with the default compression level, 6, and took 42 seconds. With compression at various levels, the time ranged from 25 seconds to nearly two minutes (see Table 7-2). With fast processors and network connections, CompressionLevel seems an obvious win. Experiment with CompressionLevel to see which value yields the best performance for your setup.
Table 7-2. Effect of Compression and CompressionLevel
| Level | Bytes Sent | Time Spent (sec.) | Size Reduced (%) | Time Reduced (%) |
|---|---|---|---|---|
| None | 12112880 | 55 | 0 | 0 |
| 1 | 2116435 | 25 | 82.5 | 55 |
| 2 | 2091292 | 25 | 82.5 | 55 |
| 3 | 2079467 | 27 | 82.8 | 51 |
| 4 | 1881366 | 33 | 84.4 | 40 |
| 5 | 1833850 | 36 | 84.8 | 35 |
| 6 | 1824180 | 42 | 84.9 | 24 |
| 7 | 1785725 | 48 | 85.2 | 13 |
| 8 | 1756048 | 102 | 85.5 | -46 |
| 9 | 1755636 | 118 | 85.5 | -53 |
Program Locations
The auxiliary programssh-signer2 is normally located in SSH2's installation directory, along with the other SSH2 binaries. ["Setuid client"] You can change this location with the undocumented keyword SshSignerPath:
# SSH2 only SshSignerPath /usr/alternative/bin/ssh-signer2
If you use this keyword, be sure to set it to the fully qualified path of the program. If you use a relative path, hostbased authentication works only for users who have
ssh-signer2 in their search path, and cron jobs fail without ssh-signer2 in their path.
Subsystems
Subsystems are predefined commands supported by an SSH2 server. ["Subsystems"] Each installed server can implement different subsystems, so check with the system administrator of the server machine for a list.[105][105]Or examine the server machine's configuration file /etc/ssh2/sshd2_config yourself for lines beginning with subsystem-.The -s option of ssh2, undocumented at press time, invokes a subsystem on a remote machine. For example, if the SSH2 server running on server.example.com has a "backups" subsystem defined, you run it as:
$ ssh2 -s backups server.example.com
SSH1/SSH2 Compatibility
SSH2 has a few keywords relating to SSH1 compatibility. If compatibility is enabled, whenssh2 is asked to connect to an SSH-1 server, it invokes ssh1 (assuming it is available).The keyword Ssh1Compatibility turns on SSH1 compatibility, given the value yes or no. The default is yes if compatibility is compiled in; otherwise it is no:
# SSH2 only Ssh1Compatibility yes
The keyword
Ssh1Path locates the executable for ssh1, which by default is set during compile-time configuration:
# SSH2 only Ssh1Path /usr/local/bin/ssh1
If you want SSH2 agents to store and retrieve SSH1 keys, turn on agent compatibility with the keyword
Ssh1AgentCompatibility: ["SSH-1 and SSH-2 agent compatibility"]
# SSH2 only Ssh1AgentCompatibility yes
Finally,
scp2 invokes scp1 if the -1 command-line option is present:
# SSH2 only scp2 -1 myfile server.example.com:
In this case,
scp2 - simply invokes scp1, passing along all its arguments (except for the -1 of course). We don't see much point to this option: if scp1 is available, why not invoke it directly? But the option is there if you need it.
Logging and Debugging
Earlier in the chapter, we introduced the -v command-line option which causes SSH clients to print debugging messages. Verbose mode works forssh and scp :
# SSH1, OpenSSH $ ssh -v server.example.com SSH Version 1.2.27 [sparc-sun-solaris2.5.1], protocol version 1.5. client: Connecting to server.example.com [128.9.176.249] port 22. client: Connection established. ...
Verbose mode can also be turned on for SSH2 with the (surprise!)
VerboseMode keyword:
# SSH2 only VerboseMode yes
If you ever encounter problems or strange behavior from SSH, your first instinct should be to turn on verbose mode.SSH2 has multiple levels of debug messages; verbose mode corresponds to level 2. You can specify greater or less debugging with the -d command-line option, followed by an integer from to 99:
$ ssh2 -d0 No debugging messages $ ssh2 -d1 Just a little debugging $ ssh2 -d2 Same as-v $ ssh2 -d3 A little more detailed $ ssh2 -d# And so on...
The analogous feature in OpenSSH is the
LogLevel directive, which takes one of six levels as an argument: QUIET, FATAL, ERROR, INFO, VERBOSE, and DEBUG (in order of increasing verbosity). So for example:
# OpenSSH $ ssh -o LogLevel=DEBUG
is equivalent to
ssh -v.The -d option may also use the same module-based syntax as for server debugging: ["SSH2 Debug mode (module-based)"]
$ ssh2 -d Ssh2AuthPasswdServer=2 server.example.com
scp2 also supports this level of debugging, but the option is -D instead of -d since scp -d is already used to mean something else:
$ scp2 -D Ssh2AuthPasswdServer=2 myfile server.example.com
To disable all debug messages, use -q:
# SSH1, SSH2, OpenSSH $ ssh -q server.example.com # SSH2 only $ scp2 -q myfile server.example.com:
or the
QuietMode keyword:
# SSH2 only QuietMode yes
Finally, to print the program version number, use -V:
# SSH1, SSH2, OpenSSH $ ssh -V # SSH2 only $ scp2 -V
Random Seeds
SSH2 lets you change the location of your random seed file, which is ~/.ssh2/random_seed by default: ["Random seed file"]# SSH2 only RandomSeedFile /u/smith/.ssh2/new_seed