How iptables Works
How iptables WorksThe functionality frequently referred to as iptables is actually composed of two components: netfilter and iptables. Running in kernelspace (page 1039), the netfilter component is a set of tables that hold rules that the kernel uses to control network packet filtering. Running in userspace (page 1062), the iptables utility sets up, maintains, and displays the rules stored by netfilter. Rules, matches, targets, and chains
A rule comprises one or more criteria (matches or classifiers) and a single action (a target). If, when a rule is applied to a network packet, the packet matches all of the criteria, the action is applied to the packet. Rules are stored in chains. Each rule in a chain is applied, in order, to a packet, until a match is found. If there is no match, the chain's policy, or default action, is applied to the packet (page 771). History
In the kernel, iptables replaces the earlier ipchains as a method of filtering network packets and provides multiple chains for increased filtration flexibility. The iptables utility also provides stateful packet inspection (page 766). Example rules
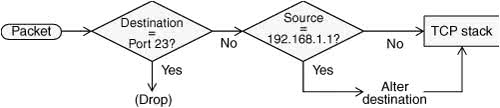
As an example of how rules work, assume that a chain has two rules (Figure 25-1). The first rule tests whether a packet's destination is port 23 (FTP) and drops the packet if it is. The second rule tests whether a packet was received from the IP address 192.168.1.1 and alters the packet's destination if it was. When a packet is processed by the example chain, the kernel applies the first rule in the chain to see if the packet arrived on port 23. If the answer is yes, the packet is dropped and that is the end of processing for that packet. If the answer is no, the kernel applies the second rule in the chain to see if the packet came from the specified IP address. If yes, the destination in the packet's header is changed and the modified packet is sent on its way. If no, the packet is sent on without being changed. Figure 25-1. Example of how rules work
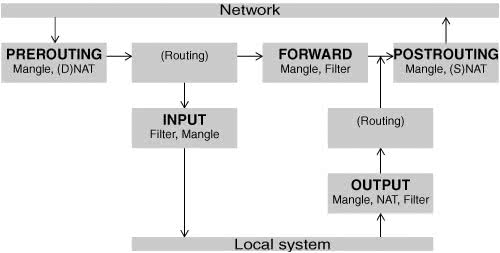
Chains are collected in three tables: Filter, NAT, and Mangle. Each of the tables has builtin chains (described next). You can create additional, user-defined chains in Filter, the default table. Filter
The default table. This table is mostly used to DROP or ACCEPT packets based on their content; it does not alter packets. Builtin chains are INPUT, FORWARD, and OUTPUT. All user-defined chains go in this table. NAT
The Network Address Translation table. Packets that create new connections are routed through this table, which is used exclusively to translate the source or destination field of the packet. Builtin chains are PREROUTING, OUTPUT, and POSTROUTING. Use this table with DNAT, SNAT, and MASQUERADE targets only.
Mangle
Used exclusively to alter the TOS (type of service), TTL (time to live), and MARK fields in a packet. Builtin chains are PREROUTING and OUTPUT. Network packet
When a packet from the network enters the kernel's network protocol stack, it is given some basic sanity tests, including checksum verification. After passing these tests, the packet goes through the PREROUTING chain, where its destination address may be changed (Figure 25-2). Figure 25-2. Filtering a packet in the kernel
Next the packet is routed based on its destination address. If it is bound for the local system, it first goes through the INPUT chain, where it can be filtered (accepted, dropped, or sent to another chain) or altered. If the packet is not addressed to the local system (the local system is forwarding the packet), it goes through the FORWARD and POSTROUTING chains, where it can again be filtered or altered. Packets that are created locally pass through the OUTPUT and POSTROUTING chains, where they can be filtered or altered before being sent to the network. State
The connection tracking machine (sometimes called the state machine) provides information on the state of a packet, allowing you to define rules that match criteria based on the state of the connection the packet is part of. For example, when a connection is opened, the first packet is part of a NEW connection, whereas subsequent packets are part of an ESTABLISHED connection. Connection tracking is handled by the conntrack module. The OUTPUT chain handles connection tracking for locally generated packets. The PREROUTING chain handles connection tracking for all other packets. For more information refer to "State"on page 774. Before the advent of connection tracking, it was sometimes necessary to open many or all nonprivileged ports to make sure that you accepted all RETURN and RELATED traffic. Because connection tracking allows you to identify these kinds of traffic, you can keep many more ports closed to general traffic, thereby increasing system security. Jumps and targets
A jump or target specifies the action the kernel takes if a packet matches all the match criteria for the rule being processed (page 775). |
Chapter 25. iptables: Setting Up a Firewall
|