

|
CONTENTS | |
 This chapter details the use of databases with Jython. Jython can use any database tool Java can, but this chapter focuses on the DBM database files, the MySQL database server and the PostgreSQL object-relational database management system (ORDBMS). This chapter also includes Jython object serialization and persistence. Topics include DBM, serialization, persistence, MySQL, PostgreSQL, the JDBC API, the zxJDBC API, and transactions.
This chapter details the use of databases with Jython. Jython can use any database tool Java can, but this chapter focuses on the DBM database files, the MySQL database server and the PostgreSQL object-relational database management system (ORDBMS). This chapter also includes Jython object serialization and persistence. Topics include DBM, serialization, persistence, MySQL, PostgreSQL, the JDBC API, the zxJDBC API, and transactions.
DBM files are hashed database files that act similarly to a dictionary object. This similarity is somewhat limited because current implementations do not use all dictionary methods and because all DBM keys and values must be strings. Various DBM tools will work with Jython, but only one is currently bundled with Jython: dumbdbm. The name isn't necessarily enticing, and the implementation is simple and slow; however, it is a moderately effective DBM clone. In the future, it is likely that other DBM modules will be available for Jython as well. The following simple interactive example using the dumbdbm module shows how using dumbdbm requires calling its module's open() method, then you can use the opened object much like a dictionary—with restrictions.
>>> import dumbdbm >>> dbm = dumbdbm.open("dbmtest") >>> dbm['Value 1'] = 'A' >>> dbm['Value 2'] = 'B' >>> dbm['Value 3'] = 'B' >>> for key in dbm.keys(): ... print key, ":", dbm[key] ... Value 3 : B Value 2 : B Value 1 : A >>> >>>dir(dbm.__class__) ['__delitem__', '__doc__', '__getitem__', '__init__', '__len__', '__module__', '__setitem__', '_addkey', '_addval', '_commit', '_setval', '_update', 'close', 'has_key', 'keys'] >>> >>> dbm.close()
The dir(dbm.__class__) method shows how the dbm object differs from a dictionary. Of the dictionary methods, only keys and has_key are implemented. The minimum special methods expected of dictionary objects (__setitem__ , __delitem__ , __getitem__ , and __len__ ) do appear. Because a DBM object behaves like a dictionary, there is no need to explain its usage, and although it lacks some of the dictionary methods, it does have one distinct advantage: It is persistent. Re-opening the dbmtest catalog shows the values previously entered:
>>> import dumbdbm >>> dbm = dumbdbm.open("dbmtest") >>> for key in dbm.keys(): ... print key, ":", dbm[key] ... Value 3 : B Value 2 : B Value 1 : A >>> dbm.close()
Opening a new dumbdbm catalog actually creates two files: one with a .dir extension, and another with a .dat extension. No extension is required in the open function, only the catalog name. Other DBM implementations allow for flags and mode arguments in the open function, but dumbdbm ignores such arguments.
Serializing makes an object into a stream suitable for transmission or storage. The storage part is what warrants including this topic with databases, as that is where such serialized objects often reside. To serialize a Jython object, use the marshal, pickle, or cPickle module. The marshal module works only on builtin types, whereas the pickle module works with built-in objects, module-global classes and functions, and most instance objects. The cPickle module is a high-performance, Java version of the pickle module. Its name is borrowed from CPython's cPickle module and does not mean it is written in C. The shelve module combines databases with pickle to create persistent object storage. Jython's PythonObjectInputStream is an ObjectInputStream that helps with resolving classes when deserializing Jython objects that inherit from Java classes.
The marshal module serializes code objects and built-in data objects. It is most frequently foregone in favor of the cPickle module described next, but it nonetheless sometimes appears in projects. Note that one draw the marshal module has for CPython is its ability to compile code objects; however, this is currently not true for Jython objects, leaving the marshal module less used. The marshal module has four methods: dump, dumps, load, and loads. The dump and load methods serialize and restore an object to and from a file. Therefore, the arguments to dump are the object to serialize and the file object, while the arguments for load are just the file object. The file object given to the dump and load functions must have been opened in binary mode. The dumps and loads methods serialize and restore an object to and from a string. The following interactive example demonstrates using marshal with a list object. Remember that the marshal module does not serialize arbitrary objects, only the common built-in objects. In the current implementation, if marshal cannot serialize the object, a KeyError is raised.
>>> import marshal >>> file = open("myMarshalledData.dat", "w+b") # Must be Binary mode >>> L = range(30, 50, 7) >>> marshal.dump(L, file) # serialize object L to 'file' >>> >>> file.flush() # flush or close after the dump to ensure integrity >>> file.seek(0) # put file back at beginning for load() >>> >>> restoredL = marshal.load(file) >>> print L [30, 37, 44] >>> print restoredL [30, 37, 44]
The pickle and cPickle modules are the preferred means of serializing Jython objects. The difference between pickle and cPickle is only implementation and performance, but there is no usage difference between the two. Most objects, except Java objects, code objects and those Jython objects that have tricky __getattr__ and __setattr__ methods, may be serialized with pickle or cPickle. Note that future references to the pickle module refer to either pickle or cPickle , but all examples will use the cPickle module because of its marked performance advantage. The pickle module defines four functions that appear in Table 11.1. The dump and dumps functions serialize objects and the load and loads functions deserialize them.
|
Method |
Description |
|---|---|
|
Dump(object, file[, bin]) |
Serializes a built-in data object to a previously opened file object. If the object cannot be serialized, a PicklingError exception is raised. pickle can use a text or binary format. A zero or missing third argument means text format, and a nonzero third argument indicates binary. |
|
Load(file) |
Reads and deserializes data from a previously opened file object. If the pickled data was written with the file in binary mode, the file object supplied to load should also be in binary mode. |
|
dumps(object[, bin]) |
Serializes an object to a string object rather than to a file. A PicklingError is raised if the object cannot be serialized. A zero or missing second argument means text format, and a nonzero second argument indicates binary. |
|
loads(string) |
Deserializes a string into a data object. |
The pickle module also defines a PicklingError exception that is raised when it encounters an object that cannot be pickled. Following is a simple interactive example using pickle to store an instance of a class called product. This example specifies binary mode for the file object and specifies the binary pickle mode by adding a non-zero, third argument to cPickle.dump:
>>> import cPickle >>> class product: ... def __init__(self, productCode, data): ... self.__dict__.update(data) ... self.productCode = productCode ... >>> data = {'name':'widget', 'price':'112.95', 'inventory':1000} >>> widget = product('1123', data) >>> f = open(widget.productCode, 'wb') >>> cPickle.dump(widget, f, 1) >>> f.close()
Now the widget product is stored in a file named 1123—the product's productCode. Restoring this instance uses the cPickle.load function, but in order to re-create the instance properly, its class must exist in the namespace where it is unpickled. Assume the following interactive example is a new session that reconstructs the widget product. The product class must be defined again to ensure it is available for the instance's reconstruction. Because the original file was opened in binary mode, subsequent access to the file must specify binary mode:
>>> import cPickle >>> class product: ... def __init__(self, productCode, data): ... self.__dict__.update(data) ... self.productCode = productCode ... >>> f = open("1123", "rb") >>> widget = cPickle.load(f) >>> f.close() >>> vars(widget) {'name': 'widget', 'productCode': '1123', 'price': '112.95', 'inventory': 1000}
An object can control its pickling and unpickling by defining the special methods __getstate__ and __setstate__. If __getstate__ is defined, its return value is what is serialized when an object is pickled. If __setstate__ is defined, it is called with the de-serialized data (what __getstate__ returned) when reconstructing an object. The __getstate__ and __setstate__ methods are complementary, but both are not required. If you do not define __setstate__, then __getstate__ must return a dictionary. If you do not define __getstate__, then __setstate__ receives a dictionary (the instance __dict__ ) when loading. You can alternatively use pickler and unpickler objects. To create these objects, supply the appropriate file object to the pickle.Pickler or pickle.Unpickler class.
>>> import cPickle >>> f = open("picklertest", "w+b") >>> p = cPickle.Pickler(f) >>> u = cPickle.Unpickler(f) >>> >>> L = range(10) >>> p.dump(L) # use pickler object to serialize >>> f.seek(0) >>> print u.load() [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
pickle handles recursive data structures, objects that contain a reference to themselves, and nested data structures, such as a dictionary that contains a list that contains a tuple and so on. A Pickler object stores a reference to all the previously pickled objects, ensuring that no serialization happens for later references to the same object, whether additional references are from recursion or nesting. Reusing a Pickler object allows shared objects to be pickled only once, and Pickler.dump() only writes a short reference for those objects it encounters that where previously pickled.
Jython's shelve module combines the convenience of DBM catalogs with pickle's serialization to create a persistent object storage. A shelve acts like a dictionary, similar to the dumbdbm module, but the difference is that a shelve allows any picklable object as values, even though keys still must be strings. Following is an interactive example of using the shelve module:
>>> import shelve, dumbdbm >>> dbm = dumbdbm.open("dbmdata") >>> shelf = shelve.Shelf(dbm) >>> shelf['a list'] = range(10) >>> shelf['a dictionary'] = {1:1, 2:2, 3:3} >>> print shelf.keys() ['a list', 'a dictionary'] >>> shelf.close()
You may alternately use the shelve open method itself, as shown here, skipping the dumbdbm.open(...) step:
>>> import shelve >>> shelf = shelve.open("dbmdata")
The process of serializing Jython objects from within Java is the same as for serializing Java objects with but one exception: org.python.util. PythonObjectInputStream. Normally, Jython objects serialize and deserialize as expected from Java, but the PythonObjectInputStream helps resolve classes when deserializing Jython objects that inherit from a Java class. This doesn't mean that it only works for those that subclass a Java object. It works with any Jython object, but is most valuable when deserializing those Jython objects with Java superclasses. Serializing a Jython object from Java requires the steps shown in the following pseudo-code:
// Import required classes import java.io.*; import org.python.core.*; // Identify the resource String file = "someFileName"; // To serialize, make an OutputStream (FileOutputStream in this case) // and then an ObjectOutputStream. FileOutputStream oStream = new FileOutputStream(file); ObjectOutputStream objWriter = new ObjectOutputStream(oStream); // Write a simple Jython object objWriter.writeObject(new PyString("some string")); // clean up objWriter.flush(); oStream.close();
Deserializing the object from the example above can use either the ObjectInputStream or the PythonObjectInputStream.The steps required appear in the following pseudo-code:
// Import required classes import java.io.*; import org.python.core.*; import org.python.util.PythonObjectInputStream; // Identify the resource String file = "someFileName; // Open an InputStrea (FileInputStream in this case) FileInputStream iStream = new FileInputStream(file); // Use the input stream to open an ObjectInputStream or a // PythonObjectInputStream. PythonObjectInputStream objReader = new PythonObjectInputStream(iStream); // It could be this for objects without java superclasses // ObjectInputStream objReader = new ObjectInputStream(iStream); // Read the object PyObject po = (PyObject)objReader.readObject(); // clean up iStream.close();
This section details using Jython to interact with the MySQL and PostgreSQL database management systems (DBMS). Jython can work with any database that has a Java driver, but these two were chosen because they are extremely popular, freely available, very stable, commonly deployed, and have a lot of documentation. Additionally, New Riders has the tutorials MySQL, by Paul DuBois, and PostgreSQL Essential Reference, by Barry Stinson. Both these tutorials are useful resources in exploring these databases, and you can investigate these tutorials further at http://www.newriders.com. Examples within this chapter are each written using a specific database, but most will actually work with either database, or even other databases not mentioned here, with slight modifications. The exception is that examples using features that exist in PostgreSQL, but not MySQL, obviously will not work without those underlying features (such as transactions). The differences between MySQL and PostgreSQL are speed and features. This might be an oversimplification when comparing complex data systems, but the general guideline is that MySQL is fast—very fast—and PostgreSQL is very advanced in respect to features. An update or select operation is faster with MySQL, but PostgreSQL provides transaction integrity, constraints, rules, triggers, and inheritance. MySQL is a SQL database server that follows the relational database model (it stores data in separate tables) while PostgreSQL is an object-relational database management system (ORDMS). MySQL uses only tabular data, but when using object-oriented languages, it is sometimes difficult to get objects to fit the tabular structure. This gives cause for ORDBMS, allowing representation of non-traditional data structures within an underlying relational model. Using PostgreSQL or MySQL has security implications because each is available to network connections. The administration of these database systems is well beyond the scope of this tutorial, but it is important to encourage those users new to these databases to explore the relevant security and administrative documentation available for each system.
MySQL is an SQL database server that runs on most UNIX-like platforms and on Windows. To run the MySQL-specific examples in this chapter, you must download and install MySQL and its associated JDBC driver, or alter the examples to work with whichever database system you decide to use. MySQL is available from http://www.mysql.com/ in the "downloads" section. The MySQL JDBC driver is located in the same downloads section of the website, but the most current driver and release information is at http://mmmysql.sf.net/. The version of the JDBC driver used in this chapter is mm.mysql-2.0.4-bin.jar. This is actually just one of the drivers available for MySQL, but it is currently the most commonly used and best JDBC driver available for MySQL. Installation instructions are unnecessary because MySQL comes as a Windows installer or in *nix package format. Just run the installer or package manager as required. The MySQL JDBC driver requires no installation, it just needs to be added to the classpath. After installing MySQL, however, you must add a user and a database. Examples in this chapter will use the user jyuser, the password beans, and the database test unless specified otherwise. To start the server, use the command appropriate to your platform from the commands below:
# *nix. "user" designates the name of the user to own the process /pathToMysql/bin/safe_mysqld & # windows \pathToMysql\bin\winmysqladmin.exe
The test database used in this chapter should be automatically created when MySQL is installed, but if for some reason the test database does not exist, create it. To create the test database, connect to the server from a command shell with the MySQL client program mysql , then enter the CREATE DATABASE command. The client program mysql is located in the bin directory within MySQL's installation directory. You need to run this program as the user who has appropriate privileges. Note that the SQL commands are terminated with ;, \g, or \G.
C:\mysql\bin>mysql Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 to server version: 3.23.39 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql> CREATE DATABASE test; Query OK, 1 row affected (0.33 sec)
You can confirm the database exists with the SHOW DATABASES statement:
mysql> SHOW DATABASES\g +----------+ | Database | +----------+ | mysql | | test | +----------+ 2 rows in set (0.00 sec)mysql>
Next, add the user jyuser. This user will require all permissions to the test database. To do this, use the GRANT statement. There are four parts to the GRANT statement that equate to what, where, who and how. Following is a summary of the GRANT statement's syntax:
GRANT what ON where TO who IDENTIFIED BY how
what designates which permissions are being granted.We shall grant ALL permissions to the user jyuser . where means in which databases and tables these permissions apply—the test database in our case. who specifies not only the username, but also the source machine from which requests may originate. The user for examples within this chapter is jyuser, and the source location should be from the machine you will use to connect to the database. The example GRANT statement below assumes all jyuser connections originate from the localhost. To add additional source addresses, use the percent sign as a wild card, such as 192.168.1.%, or even just % to allow from anywhere. Note that allowing users to connect from any host is troublesome. how is the means of authentication, or in other words, the password. This chapter uses the password beans. An example of the GRANT statement that fulfills the requirements of examples in this chapter is this:
mysql> USE test; mysql> GRANT ALL ON test TO jyuser@localhost IDENTIFIED BY "beans"; Query OK, 0 rows affected (0.05 sec)
The setup for examples in this chapter is complete. The following section follows the same setup procedures for the PostgreSQL database, so skip ahead to the section "JDBC" if you are only using the MySQL database.
PostgreSQL is a very advanced and full-featured ORDBMS. PostgreSQL runs on most UNIX-like platforms and Windows 2000/NT. The PostgreSQL examples that appear in this chapter require the use of a PostgreSQL server and the PostgreSQL JDBC driver, which are available from http://www.postgresql.org/. This chapter assumes an installation on a *nix system. Because Windows lacks much of the UNIX-like functionality, installing PostgreSQL on Windows requires additional packages and is generally more troublesome. To install on a UNIX-like system, download the package format appropriate for your system and run your package manager. To Install PostgreSQL on a Windows 2000/NT system, first download the Cygwin and cygipc packages required to emulate a UNIX environment on a Windows OS. The Cygwin package is available at http://sources.redhat.com/cygwin/ and the cygipc package is available at http://www.neuro.gatech.edu/users/cwilson/cygutils/V1.1/cygipc/. Then follow the instructions found in the file doc/FAQ_MSWIN within the PostgreSQL distribution or the instructions found in Chapter 2 of the PostgreSQL Administrator's guide that is freely available at http://www.ca.postgresql.org/users-lounge/docs/7.1/admin/installwin32.html. After the server has been installed, you will need to initialize a database cluster. This should be done as the user who administers the PostgreSQL database—usually postgres. You should not perform administrative operations on the database as root or administrator. The command to initialize a database cluster is the following:
initdb -D /path/to/datadirectory
The initdb file comes with PostgreSQL. The data directory is usually /usr/local/pgsql/data, making the command as follows:
initdb -D /usr/local/pgsql/data
Within the data directory created with the preceding command is the file pg_hba.conf. This file controls which hosts connect to the database. Before you can connect to the database with the JDBC driver, there must be a host entry in the pg_hba.conf file for the machine you will use to connect from. A host entry requires the word "host," the database name that host is allows to connect to, the IP address of the connection machine, a bit mask indicating significant bits in the IP address, and the authentication type. If you will connect from the local machine, the host entry would look like this:
host test 127.0.0.1 255.255.255.255 crypt
The authentication type can be any of the following:
Trust No authentication required.
Password Match username with a password.
Crypt Same as "password," but the password in encrypted when sent over the network.
Ident Authenticate with the ident server.
Krb4 Use Kerberos V4 authentication.
Krb5 Use Kerberos V5 authentication.
Reject Connections from the specified IP are rejected.
Next, you will need to create the user jyuser. PostgreSQL comes with a utility program appropriately called createuser that you should use to create the new user. The command to do so is as follows:
[shell prompt]$ createuser -U postgres -d -P jyuser Enter password for user "jyuser": Enter it again: Shall the new user be allowed to create more new users? (y/n) n CREATE USER
The password beans was entered at the password prompts, but it is not echoed back to the terminal. The output CREATE USER confirms that the action was successful. With the creation of a new user, you can now minimize tasks done as the postgres user. Performing subsequent tasks as jyuser is safer, such as the creation of the test database. To create the test database, use the PostgreSQL utility program createdb. The command to create the test database with the createdb program is as follows:
[shell prompt]$ createdb -U jyuser test CREATE DATABASE
The output CREATE DATABASE confirms that the creation was successful. Now you can start the server. You should start the server under the username of the person who administers the server—most often postgres. To start the server, use the following command (replace the data directory path with the one you chose for your installation):
postmaster -i -D /usr/local/pgsql/data &
You must use the -i option because that is the only way PostgreSQL will accept network socket connections (required to connect with JDBC). Now PostgreSQL is ready for the examples in this chapter.
Java uses the JDBC and java.sql package to interact with SQL databases. This means Jython can also use JDBC and the java.sql package. Using the JDBC API and java.sql package to interact with SQL databases requires only the appropriate JDBC driver for the database used (and the database of course). Examples in this chapter rely on the MySQL and PostgreSQL drivers described in the earlier section "Database Management Systems." The actual interaction matches those steps taken in Java, only using Jython's syntax. Interacting requires a connection, a statement, a result set, and the ever present need to handle errors and warnings. Those are the basics, and using those basics from Jython is what appears in this section. Additionally, advanced features such as transactions, stored procedures appear here as well.
A database connection requires a JDBC URL and most likely a username and password. Before continuing with the connection process, you should understand JDBC URLs.
A URL is a string that uniquely identifies a database connection. The syntax is as follows:
jdbc:<subprotocol>:<subname>
The URL begins with jdbc:, followed by the subprotocol, which most often coincides with the database vendor product name (such as Oracle, MySQL, PostgreSQL). Beyond that, URLs are driver-specific, meaning that the subname depends on the subprotocol. Below is the JDBC URL syntax for the MySQL database and the URL syntax for the PostgreSQL database:
jdbc:mysql://[hostname][:port]/databaseName[parameter=value] jdbc:postgresql://[hostname][:port]/databaseName[parameter=value]
There is only one word difference between these two URLs and that is the subprotocol (product) name. To connect to the test database on the local machine, use command below with the protocol matching the database system you wish to connect to:
jdbc:mysql://localhost:3306/test jdbc:postgresql://localhost:5432/test
The default host is localhost, so it is actually not required in the URL. The default ports for MySQL and PostgreSQL are 3306 and 5432 respectively, so those numbers are also unnecessary as the default value is correct. This shortens localhost connections to the test database to the following:
jdbc:mysql:///test jdbc:postgresql:///test
Note that the number of slashes remains the same, but the colon that separates the host and port number is omitted when no port specified. Below are some example JDBC URLs for other database drivers. These URLs assume that the database name is test:
Driver: COM.ibm.db2.jdbc.net.DB2Driver URL: jdbc:db2//localhost/test Driver: oracle.jdbc.driver.OracleDriver URL: jdbc:oracle:thin:@localhost:ORCL Driver: sun.jdbc.odbc.JdbcOdbcDriver URL: JDBC:ODBC:test Driver: informix.api.jdbc.JDBCDriver URL: jdbc:informix-sqli://localhost/test
At the end of a JDBC URL, you may specify connection parameters. Parameters can be any number of the database driver's allowed parameters separated by the & character. Table 11.2 shows each parameter, its meaning, its default value, and which of the two databases (MySQL or PostgreSQL) allows this parameter. The java.sql package also contains the class DriverPropertyInfo, which is another way of exploring and setting connection properties.
|
Parameter |
Meaning |
Default Value |
Database |
|---|---|---|---|
|
User |
Your database user name |
none |
Both |
|
password |
Your password |
none |
Both |
|
autoReconnect |
Attempt to reconnect if the connection dies? (true|false) |
false |
MySQL |
|
maxReconnects |
How many times should the driver try to reconnect? (Assuming autoReconnect is true.) |
3 |
MySQL |
|
initialTimeout |
How many seconds to wait before reconnecting? (Assuming autoReconnct is true.) |
2 |
MySQL |
|
maxRows |
The maximum number of rows to return (0 = all rows) |
0 |
MySQL |
|
useUnicode |
Use Unicode—true or false? |
false |
MySQL |
|
characterEncoding |
Use which Unicode character encoding (if useUnicode is true) |
none |
MySQL |
The following is an example URL that specifies the test database on the local machine, and it specifies to use Unicode character encoding for strings. The port is missing, but that is only required if it is other than the default:
jdbc:mysql://localhost/test?useUnicode=true jdbc:postgresql://localhost/test?useUnicode=true
If the hostname is again excluded because localhost is already the default value, then these URLs become the following:
jdbc:mysql:///test?useUnicode=true jdbc:postgresql:///test?useUnicode=true
Specifying the products database on a machine with the IP address 192.168.1.10, on port 8060, username bob and password letmein would look like this:
jdbc:mysql://192.168.1.10:8060/products?user=bob&password=letmein jdbc:postgresql://192.168.1.10:8060/products?user=bob&password=letmein
In practice, the username and password are rarely specified as parameters because the actual connection methods already accept such parameters. Parameters can be burdensome in the URL string.
The steps to establishing a database connection using Java's database connectivity are as follows:
Include the appropriate driver in the classpath.
Register the driver with the JDBC DriverManager.
Supply a JDBC URL, username, and password to the java.sql.DriverManager.getConnection method.
You must ensure that an appropriate database driver exists in the classpath, either as an environment variable, or with Java's -classpath option in a Jython startup script. The filenames of the jar files for the MySQL and PostgreSQL JDBC drivers used in this chapter are mm.mysql-2_0_4-bin.jar and jdbc7.1-1.2.jar. Adding these jar files to the classpath requires the following shell commands:
# For MySQL set CLASSPATH=\path\to\mm_mysql-2_0_4-bin.jar;%CLASSPATH% # For PostgreSQL set CLASSPATH=\path\to\jdbc7.1-1.2.jar;%CLASSPATH%
Once the drivers exist in the classpath , using JDBC requires that the drivers are also loaded, or registered with the DriverManager. There are two basic ways of loading the driver. You can set the jdbc.drivers property to the appropriate driver on the command line with the -D switch, or you can use the java.lang.Class.forName(classname) method. Registering a driver with the -D options would require creating a new batch or script file to launch Jython. Two commands appear below, one which registers the MySQL driver, and another that registers the PostgreSQL driver.
dos>java -Djdbc.drivers=org.gjt.mm.mysql.Driver \ -Dpython.home=c:\jython-2.1 \ -classpath c:\jython-2.1\jython.jar;\path\to\mm.mysql-2_0_4-bin.jar \ org.python.util.jython dos>java -Djdbc.drivers=org.postgresql.Driver \ -Dpython.home=c:\jython-2.1 \ -classpath c:\jython-2.1\jython.jar;\path\to\jdbc7.1-1.2.jar \ org.python.util.jython
You can also use Java's dynamic Class.forName(classname) syntax to load a driver. Remember that classes in the java.lang package are not automatically available in Jython as they are in Java, so you must import java.lang.Class or one of its parent packages before calling this method. The following example loads the MySQL and PostgreSQL drivers with Class.forName:
import java try: java.lang.Class.forName("org.gjt.mm.mysql.Driver") java.lang.Class.forName("org.postgresql.Driver") except java.lang.ClassNotFoundException: print "No appropriate database driver found" raise SystemExit
Just as it would in Java, the preceding example catches the Java ClassNotFoundException. With the driver in the classpath and registered with the DriverManager, we are ready to connect to the database. For this, use the java.sql.DriverManager's getConnection method.The getConnection method has three signatures:
public static Connection getConnection(String url) throws SQLException public static Connection getConnection(String url, Properties info) throws SQLException public static Connection getConnection( String url, String user, String password) throws SQLException
Assume the local database test exists, and that you are connecting to this database as jyuser with the password beans. The possible syntaxes for connecting are as follows:
from java.sql import DriverManager from java.util import Properties # Using the getConnection(URL) method mysqlConn = DriverManager.getConnection(
"jdbc:mysql://localhost/test?user=jyuser&password=beans") postgresqlConn = java.sql.DriverManager.getConnection(
"jdbc:postgresql://localhost/test?user=jyuser&password=beans") # Using the getConnection(URL, Properties) method params = Properties() params.setProperty("user", "jyuser") params.setProperty("password", "beans") mysqlConn = DriverManager.getConnection("jdbc:mysql://localhost/test", params) postgresqlConn = DriverManager.getConnection("jdbc:postgresql://localhost/test", params) # Using the getConnection(URL, String, String) method mysqlConn = DriverManager.getConnection("jdbc:mysql://localhost/test", "jyuser", "beans") postgresqlConn = DriverManager.getConnection("jdbc:postgresql://localhost/test", "jyuser", "beans")
Each of these methods returns a database connection that allows you to then interact with the database system.
Jython's interactive interpreter makes an ideal database client tool. Both MySQL and PostgreSQL have interactive, console client apps that are included with them, so using Jython's interactive interpreter would parallel those tools. However, you would also inherit Jython functions, classes, and so on, and have a consistent interface for any database with a JDBC driver. The only thing Jython needs to become an interactive client is a connection. Typing in the database connection statements interactively in Jython each time you need to work with a database isn't a very good approach. Alternatively, you could use Jython's * -i command-line option. When run with the -i option, Jython continues in interactive mode, even after the execution of a script. This allows you to setup database connection in a script, and continue to interact with the objects created by the script after its execution. The problem with the -i switch is that there is no mechanism to explicitly close database resources automatically. When working with databases, it is considered best to always explicitly close any database resource, so this would mean typing in the close method before quitting the interpreter each time you are finished working with the database—still not the best approach. Wrapping an interactive console in the required connection and close statements, or using Java's Runtime.addShutdownHook could ensure connections are closed. Because the addShutdownHook is not available in all versions of Java, the best approach seems to be wrapping an InteractiveConsole instance in the required connection and close statements. Listing 11.1 does just that. The database connection and a statement object are created, then the inner InteractiveConsole is started with those objects in its namespace. When this inner InteractiveConsole exits, the connection and statement objects are closed.
# File: mystart.py from java.lang import Class from java.sql import DriverManager from org.python.util import InteractiveConsole import sys url = "jdbc:mysql://localhost/%s" user, password = "jyuser", "beans" # Register driver Class.forName("org.gjt.mm.mysql.Driver") # Allow database to be optionally set as a command-line parameter if len(sys.argv) == 2: url = url % sys.argv[1] else: url = url % "test" # Get connection dbconn = DriverManager.getConnection(url, user, password) # Create statement try: stmt = dbconn.createStatement() except: dbconn.close() raise SystemExit # Create inner console interp = InteractiveConsole({"dbconn":dbconn, "stmt":stmt}, "DB Shell") try: interp.interact("Jython DB client") finally: # Close resources stmt.close() dbconn.close() print
To connect to the test database, all you need to do is make sure the appropriate driver is in the classpath , then run jython mystart.py. Following is a sample interactive session that uses mystart.py.
shell-prompt> jython mystart.py Jython DB Client >>> dbconn.catalog 'test' >>> # Exit the interpreter on the next line >>>
A PostgreSQL startup script would be similar to the one in Listing 11.1 except for the postgresql name in the JDBC URL. Note that dbconn.catalog with PostgreSQL is empty.
Another common connection task is acquiring connection information with a dialog box. Client apps requiring a database login often acquire connection information with a dialog window. The frequency of this task warrants an example, and Listing 11.2 is just that. Listing 11.2 is a dialog window that establishes a database connection and returns that connection to a registered client object. The client object is any callable object that accepts one parameter: the connection. When the connection is successfully retrieved, the dialog box then forwards this connection to the registered client object. It is then the client's duty to close the connection. Acquiring the connection occurs in the login method of the DBLoginDialog class in Listing 11.2. Two important try/except clauses exist in the login method. The first try/except catches the ClassNotFoundException in case the appropriate driver doesn't exist in the classpath, and the second try/except catches any SQLException that occurs while trying to actually get a connection to the database. The dummyClient function defined in Listing 11.2 serves as the dialog's client for when the module is ran as the main script. A successful connection is passed to the dummyClient, and it is then the dummyClient's duty to close that object.
# File: DBLoginDialog.py import sys import java from java import awt from java import sql import pawt class DBLoginDialog(awt.Dialog): '''DBLoginDialog prompts a user of database information and establishes a database login. A connection receiver is registered as client- for example: def connectionClient(dbconnection): # do something with database connection dbl = DBLoginDialog(parentframe, message) dbl.client = connectionClient''' def __init__(self, parentFrame, message): awt.Dialog.__init__(self, parentFrame) self.client = None self.background = pawt.colors.lightgrey bag = pawt.GridBag(self, anchor='WEST', fill='NONE') # Make required components self.Hostname = HighlightTextField("localhost", 24) self.DBMS = awt.Choice(itemStateChanged=self.updatePort) self.Port = HighlightTextField("3306", 5) self.Database = HighlightTextField("test",12) self.User = HighlightTextField("jyuser", 10) self.Password = HighlightTextField("", 10, echoChar='*') # Fill the choice component with opions self.DBMS.add("MySQL") self.DBMS.add("PostgreSQL") # add message bag.addRow(awt.Label(message), anchor='CENTER') # Put components in the bag for x in ["Hostname", "DBMS", "Port", "Database", "User", "Password"]: bag.add(awt.Label(x + ":")) bag.addRow(self.__dict__[x]) # Add action buttons bag.add(awt.Button("Login", actionPerformed=self.login), fill='HORIZONTAL') bag.addRow(awt.Button("Cancel", actionPerformed= self.close), anchor='CENTER') self.pack() bounds = parentFrame.bounds self.bounds = (bounds.x + bounds.width/2 - self.width/2, bounds.y + bounds.height/2 - self.height/2, self.width, self.height) def login(self, e): db = self.DBMS.selectedItem if db == "MySQL": driver = "org.gjt.mm.mysql.Driver" else: driver = "org.postgresql.Driver" try: java.lang.Class.forName(driver) except java.lang.ClassNotFoundException: self.showError("Unable to load driver %s" %% driver) return url = "jdbc:%s://%s:%s/%s" %% (db.lower(), self.Hostname.text, self.Port.text, self.Database.text) try: dbcon = sql.DriverManager.getConnection(url, self.User.text, self.Password.text) self.dispose() self.client(dbcon) except sql.SQLException: self.showError("Unable to connect to database") def updatePort(self, e): if self.DBMS.selectedItem == 'MySQL': port = '3306' elif self.DBMS.selectedItem == 'PostgreSQL': port = '5432' self.Port.text= port def setClient(client): self.client = client def showError(self, message): d = awt.Dialog(self.parent, "Error") panel = awt.Panel() panel.add(awt.Label(message)) button = awt.Button("OK") panel.add(button) d.add(panel) d.pack() bounds = self.parent.bounds d.bounds = (bounds.x + bounds.width/2 -d.width/2, bounds.y + bounds.height/2 - d.height/2, d.width, d.height) d.windowClosing = lambda e, d=d: d.dispose() button.actionPerformed = d.windowClosing d.visible = 1 def close(self, e): self.dispose() class HighlightTextField(awt.TextField, awt.event.FocusListener): def __init__(self, text, chars, **kw): awt.TextField.__init__(self, text, chars) self.addFocusListener(self) for k in kw.keys(): exec("self." ++ k + "=kw[k]") def focusGained(self, e): e.source.selectAll() def focusLost(self, e): e.source.select(0, 0) def dummyClient(connection): if connection != None: print "\nDatabase connection successfully received by client." print "Connection=", connection connection.close() print "Database connection properly closed by client." if __name__ == '__main__': # make a dummy frame to parent the dialog window f = awt.Frame("DB Login", windowClosing=lambda e: sys.exit()) screensize = f.toolkit.screenSize f.bounds = (screensize.width/2 - f.width/2, screensize.height/2 - f.height/2, f.width, f.height) # create and show the dialog window dbi = DBLoginDialog(f, "Connection Information") dbi.client = dummyClient dbi.windowClosing = dbi.windowClosed = lambda e: sys.exit() dbi.visible = 1
To execute the DBLoginDialog, you must make sure the appropriate database drivers are in the classpath , then execute jython DBLoginDialog.py. You should see the login window shown in Screenshot
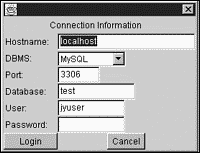
Once connected, you may explore information about the database and connection, or metadata. A Java connection object (java.sql.Connection) has the method getMetaData, which returns a java.sql.DatabaseMetaData object. The DatabaseMetaData object provides thorough information about its related database connection. The DatabaseMetaData object has numerous methods, and you should consult its javadoc page for full details. Metadata becomes very important when learning a new database tool and when trying to support multiple databases. You can interactively explore metadata with Jython to discover a database's features and properties. Suppose you need to know a MySQL's system functions, numeric functions, and support for transactions. Interactively discovering this looks like the following:
>>> import java >>> from java.sql import DriverManager >>> >>> # Register driver >>> java.lang.Class.forName("org.gjt.mm.mysql.Driver") <jclass org.gjt.mm.mysql.Driver at 650329> >>> >>> # Get Connection >>> url, user, password = "jdbc:mysql:///test", "jyuser", "beans" >>> dbconn = DriverManager.getConnection(url, user, password) >>> >>> # Get the DatabaseMetaData object >>> md = dbconn.getMetaData() >>> >>> # Use the metadata object to find info about MySQL >>> print md.systemFunctions DATABASE,USER,SYSTEM_USER,SESSION_USER,PASSWORD,ENCRYPT,LAST_INSERT_ID, VERSION >>> md.numericFunctions 'ABS,ACOS,ASIN,ATAN,ATAN2,BIT_COUNT,CEILING,COS,COT,DEGREES,EXP,FLOOR,LOG, LOG10,MAX,MIN,MOD,PI,POW,POWER,RADIANS,RAND,ROUND,SIN,SQRT,TAN,TRUNCATE' >>> md.supportsTransactions() 0 >>> >>> # Don't forget to close connections >>> dbconn.close()
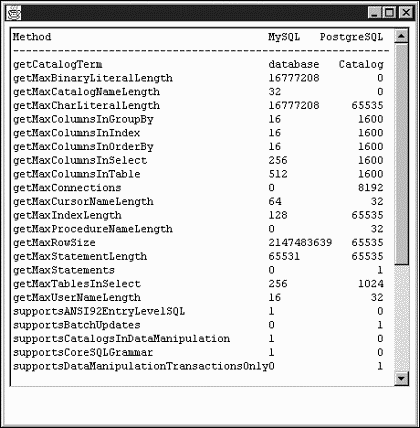
Of the overwhelming number of methods in the DatabaseMetaData Object, only some illuminate differences between the MySQL and PostgreSQL databases. Listing 11.3 uses the methods that highlight differences to create a visual report comparing MySQL and PostgreSQL. Many differences are somewhat trivial, but other, such as transactions, schema, and unions, are not. Listing 11.3 uses the DBLoginDialog defined in Listing 11.1 to create the connections. The DBLoginDialog.py file must therefore be in the sys.path, preferably the current working directory. When running Listing 11.3, you are given two dialog boxes for database connections. The first must select a MySQL database, and the second, a PostgreSQL database. The script then produces the report by looping through a list of the desired methods. Within this loop, Jython's exec statement executes a constructed statement string. What is normally:
value = metaData.supportsTransactions()
becomes something like this:
cmd = "supportsTransactions" exec("value = metaData.%s()" %% cmd)
The results for each database then appear in a TextArea after all the information is collected.
# File: jdbcMetaData.py from DBLoginDialog import DBLoginDialog from java import awt import sys class MetaData(awt.Frame): def __init__(self): self.windowClosing=lambda e: sys.exit() self.databases = ["MySQL", "PostgreSQL"] self.panel = awt.Panel() self.infoArea = awt.TextArea("", 40, 60, awt.TextArea.SCROLLBARS_VERTICAL_ONLY, font=("Monospaced", awt.Font.PLAIN, 12)) self.panel.add(self.infoArea) self.add(self.panel) self.pack() screensize = self.toolkit.screenSize self.bounds = (screensize.width/2 - self.width/2, screensize.height/2 - self.height/2, self.width, self.height) self.data = {} self.visible = 1 self.dialog = DBLoginDialog(self, "Select a Connection") self.dialog.client = self.gatherMetaInfo self.dialog.visible = 1 def showResults(self): infoWidth = self.infoArea.columns info = 'Method' ++ 'MySQL PostgreSQL\n'.rjust(infoWidth - 7) info += '-' ** (infoWidth - 1) + '\n' keys = self.data.keys() keys.sort() for x in keys: info += x mysql = str(self.data[x]['MySQL']) postgresql = str(self.data[x]['PostgreSQL']) results = mysql.ljust(18 - len(postgresql)) + postgresql info += results.rjust(self.infoArea.columns - len(x) - 2) info += "\n" self.infoArea.text = info def nextDatabase(self): if len(self.databases): self.dialog.visible = 1 else: self.showResults() def gatherMetaInfo(self, dbconn): if dbconn==None: return metaData = dbconn.getMetaData() dbname = metaData.databaseProductName for cmd in self.getCommands(): value = "" try: exec("value = metaData.%s()" %% cmd) except: value = "Test failed" if self.data.has_key(cmd): self.data[cmd][dbname] == value else: self.data.update({cmd:{dbname:value}}) dbconn.close() # close the database! self.databases.remove(dbname) self.nextDatabase() def getCommands(self): return ['getCatalogTerm', 'getMaxBinaryLiteralLength', 'getMaxCatalogNameLength', 'getMaxCharLiteralLength', 'getMaxColumnsInGroupBy', 'getMaxColumnsInIndex', 'getMaxColumnsInOrderBy', 'getMaxColumnsInSelect', 'getMaxColumnsInTable', 'getMaxConnections', 'getMaxCursorNameLength', 'getMaxIndexLength', 'getMaxProcedureNameLength', 'getMaxRowSize', 'getMaxStatementLength', 'getMaxStatements', 'getMaxTablesInSelect', 'getMaxUserNameLength', 'supportsANSI92EntryLevelSQL', 'supportsBatchUpdates', 'supportsCatalogsInDataManipulation', 'supportsCoreSQLGrammar', 'supportsDataManipulationTransactionsOnly', 'supportsDifferentTableCorrelationNames', 'supportsFullOuterJoins', 'supportsGroupByUnrelated', 'supportsMixedCaseQuotedIdentifiers', 'supportsOpenStatementsAcrossCommit', 'supportsOpenStatementsAcrossRollback', 'supportsPositionedDelete', 'supportsUnion', 'supportsSubqueriesInComparisons', 'supportsTableCorrelationNames', 'supportsTransactions'] if __name__ == '__main__': md = MetaData()
To execute Listing 11.3, ensure that both the database drivers are in the class-path.Then run the following command:
jython jdbcMetaData.py
You should first see the same dialog window as in Listing 11.2. Enter a MySQL connection there. The dialog will return; enter a PostgreSQL connection then. Following that, you should see a metadata comparison between the two databases that is similar to that shown in Screenshot.
The bulk of interacting with MySQL and PostgreSQL involves SQL statements . Issuing SQL statements requires a statement object. To create a statement object, use the connection's createStatement() method.
>>> import java >>> java.lang.Class.forName("org.gjt.mm.mysql.Driver") <jclass org.gjt.mm.mysql.Driver at 1876475> >>> db, user, password = "test", "jyuser", "beans" >>> url = "jdbc:mysql://localhost/%s" %% db >>> dbconn = java.sql.DriverManager.getConnection(url, user, password) >>> stmt = dbconn.createStatement()
The createStatement method may also set type and concurrency parameters for the result set. Before a result set can use its update* methods, the statement must be created with concurrency set to updatable. The following example creates an updateable result set by setting the type and concurrency:
>>> import java >>> from java import sql >>> java.lang.Class.forName("org.gjt.mm.mysql.Driver") <jclass org.gjt.mm.mysql.Driver at 1876475> >>> db, user, password = "test", "jyuser", "beans" >>> url = "jdbc:mysql://localhost/%s" %% db >>> dbconn = sql.DriverManager.getConnection(url, user, password) >>> >>> type = sql.ResultSet.TYPE_SCROLL_SENSITIVE >>> concurrency = sql.ResultSet.CONCUR_UPDATABLE >>> stmt = dbconn.createStatement(type, concurrency)
The statement object allows you to execute SQL statements with its execute(), executeQuery(), and executeUpdate() methods. These three methods differ in what they return. The execute() method returns 0 or 1 indicating whether or not there is a ResultSet. Actually, it returns a Java Boolean that Jython interprets as 1 or 0.The executeQuery() method always returns a ResultSet, and the executeUpdate() method returns an integer indicating the number of affected rows.
>>> query = "CREATE TABLE random ( number tinyint, letter char(1) )" >>> stmt.execute(query) 0
In the preceding example, the query updates the database, meaning there is no ResultSet. You can confirm this with the statement's getResultSet() method or resultSet automatic bean property.
>>> print stmt.resultSet None
Now that a table exists, you can fill the table with data. This would use the executeUpdate() method. The following interactive example continues previous examples (the statement object already exists) by adding some data to the random table:
>>> import string, random >>> for i in range(20): ... number = random.randint(0, 51) ... query = "INSERT INTO random (number, letter) VALUES (%i, '%s')" ... query = query % (number, string.letters[number - 1]) ... stmt.executeUpdate(query) 1 ...
You should see an output of many 1s, indicating that one row was altered for each update. Note the use of single quotes around the '%s' in the query string. The letter, as all strings, must be in quotes. Using internal single quotes makes this easy, but what if the string is a single quote. A single quote for the letter would create an SQLException. Single quotes must be doubled in query strings, meaning the string "It's a bird" should be "It's a bird" in query strings. Even then, you must negotiate this within Jython's syntax, and include escaped double quotes to maintain proper SQL format. Using escaped double quotes to allow for a single quote string is shown here:
>>> query = "INSERT INTO random (number, letter) VALUES (%i, \"%s\")" >>> query = query % (4, "''")
Now that the random table has data, you can use the executeQuery() method to select that data. Still continuing the same interactive session from above, the following example selects all the data from the random table:
>>> rs = stmt.executeQuery("SELECT * FROM random")
Now we need to use the ResultSet object () to inspect the results of the SELECT statement.
When you use executeQuery , the object returned is a ResultSet. The java.sql.ResultSet object contains numerous methods to navigate through the results and retrieve them as Java native types. Remember that Jython automatically converts Java native types to appropriate Jython types. Using the ResultSet 's getByte() returns a value that becomes a PyInteger, getDouble() returns a PyFloat, and so on, all according to the Java type conversion rules listed in , "Operators, Types, and Built-In Functions." To query the random table created earlier, and loop through all its entries uses the ResultSet's next() and get* methods. In the following example, the number field is retrieved with getInt() and the letter field is retrieved with getString(). This creates the Jython types PyInteger and PyString :
>>> import java >>> java.lang.Class.forName("org.gjt.mm.mysql.Driver") <jclass org.gjt.mm.mysql.Driver at 1876475> >>> db, user, password = "test", "jyuser", "beans" >>> url = "jdbc:mysql://localhost/%s" % db >>> dbconn = java.sql.DriverManager.getConnection(url, user, password) >>> stmt = dbconn.createStatement() >>> >>> rs = stmt.executeQuery("SELECT * FROM random") >>> while rs.next(): ... print rs.getString('letter'), ": ", rs.getInt('number') ... ... U : 46 K : 36 h : 7 Q : 42 l : 11 u : 20 n : 13 z : 25 U : 46 Y : 50 j : 9 o : 14 i : 8 s : 18 d : 3 A : 26 K : 36 j : 9 n : 13 g : 6 >>> stmt.close() >>> dbconn.close()
Note that your output will look different due to the use of the random module. Navigation through the set involves moving through records with the ResultSet's navigation methods. These differ depending on which version of the JDBC you are using, and the type of statement you created. Before JDBC 2.0, navigation is restricted to just the next() method. Current JDBC versions work with next(), first(), last(), previous(), absolute(), relative(), afterLast(), beforeFirst(), moveToCurrentRow(), and moveToInsertRow(). Of these, moveToInsertRow() and moveToCurrentRow() are not implemented in the PostgreSQL driver, and require special conditions with the MySQL driver. Most of these navigation methods are obvious from their names, but four of these methods are less obvious. The relative(int) navigation method moves the cursor int number of rows from the current position. The absolute(int) moves the cursor to the int's row of the result set regardless of the current position. The moveToInsertRow(), currently available with MySQL, moves the cursor to a special row that is a construction zone unrelated to data retrieved from the database. In this area, you build a row that you intend to insert. After you have called moveToInsertRow(), and wish to return to the row you were at before jumping to the construction zone, use moveToCurrentRow(). Note that the moveToInsertRow() and moveToCurrentRow() methods require an updateable ResultSet object. Besides navigating through rows, the result set can update rows if the driver supports this. Currently, PostgreSQL does not, but the MySQL driver does. There are conditions, however, that restrict which result sets are updateable. In MySQL a result set is updateable only if the query includes only one table, the query does not use a join and the query selects the table's primary key. An additional requirement that applies to all JDBC drivers is that the statement must set the concurrency type to ResultSet.CONCUR_UPDATABLE. To perform inserts, you must also ensure that the query generating the updateable result set includes all rows without default values and all NON NULL rows. Because the random table created earlier lacks a primary key, it must be altered to include one before its result set can be updateable. The following interactive example shows the update to the random table followed by scrolling and update demonstrations:
>>> import java >>> from java import sql >>> java.lang.Class.forName("org.gjt.mm.mysql.Driver") <jclass org.gjt.mm.mysql.Driver at 1876475> >>> user, password = "jyuser", "beans" >>> url = "jdbc:mysql://localhost/test" >>> dbconn = sql.DriverManager.getConnection(url, user, password) >>> >>> type = sql.ResultSet.TYPE_SCROLL_SENSITIVE >>> concurrency = sql.ResultSet.CONCUR_UPDATABLE >>> stmt = dbconn.createStatement(type, concurrency) >>> >>> # Update table to include primary key (excuse the wrap) >>> query = "ALTER TABLE random ADD pkey INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY" >>> stmt.execute(query) 0 >>> >>> # Now get an updatable result set. >>> rs = stmt.executeQuery("select * from random") >>> rs.concurrency # 1008 is "updatable" 1008 >>> >>> # Insert a row >>> rs.moveToInsertRow() >>> rs.updateInt('number', 7) >>> rs.updateString('letter', 'g') >>> rs.updateInt('pkey', 22) >>> rs.insertRow() # This puts it in the database >>> rs.moveToCurrentRow() >>> >>> rs.relative(5) # scroll 5 rows 1 >>> # Print current row data >>> # Remember, data is random- odds are yours will differ >>> print rs.getString('letter'), rs.getInt('number') h 8 >>> rs.updateInt('number', 3) >>> rs.updateString('letter', 'c') >>> rs.updateRow() # this puts it in the database >>> stmt.close() >>> dbconn.close()
Pre-compiling SQL statements that are frequently used often helps with efficiency. A java.sql.PreparedStatement allows you to create such a prepared statement. To create a prepared statement, use the connection object's prepareStatement method, instead of createStatement. A simple prepared statement that updates a row in the random database would look like this:
>>> import java >>> from java import sql >>> java.lang.Class.forName("org.postgresql.Driver") <jclass org.gjt.mm.mysql.Driver at 1876475> >>> dbconn = sql.DriverManager.getConnection(url, user, password) >>> query = "INSERT INTO random (letter, number) VALUES (?, ?)" >>> preppedStmt = dbconn.prepareStatement(query)
Notice the question marks (?) in the query. A prepared statement allows you to leave placeholders for values that you can fill at execution time. Filling these placeholders requires that you set the value for each placeholder based on their positional identity with the set* methods. A set method exists for each supported Java type. Additionally, you should first clear parameters before setting new parameters and executing the update:
>>> # continued from previous interactive example >>> preppedStmt.clearParameters() >>> preppedStmt.setString(1, "f") >>> preppedStmt.setInt(2, 6) >>> preppedStmt.executeUpdate() 1 >>> preppedStmt.close() >>> dbconn.close()
Transactions are database operations where a set of statements must all complete successfully, or the entire operation is undone (rolled back). PostgreSQL is the database we will use for transaction examples, so that means the random table must now be created in the PostgreSQL test database. Following is an interactive example of creating the random table:
>>> import java >>> from java import sql >>> java.lang.Class.forName("org.postgresql.Driver") <jclass org.postgresql.Driver at 5303656> >>> db, user, password = "test", "jyuser", "beans" >>> url = "jdbc:postgresql://localhost/%s" %% db >>> dbconn = sql.DriverManager.getConnection(url, user, password) >>> stmt = dbconn.createStatement() >>> query = "CREATE TABLE random ( number int, letter char(1), pkey INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY)" >>> stmt.execute(query) 0 >>> import string, random >>> for i in range(20): ... number = random.randint(0, 51) ... query = "INSERT INTO random (number, letter) VALUES (%i, '%s')" ... query = query % (number, string.letters[number - 1]) ... stmt.executeUpdate(query) 1 1 ... >>> stmt.close() >>> dbconn.close()
To use JDBC transactions from Jython, you must set the connections autoCommit bean property to 0, begin the set of statements, and call the connection's rollback() method if any of the statements fail. Following is a simple example of a transaction with PostgreSQL and the random table:
>>> import java >>> from java import sql >>> java.lang.Class.forName("org.postgresql.Driver") <jclass org.postgresql.Driver at 5711596> >>> url = "jdbc:postgresql://localhost/test" >>> con = sql.DriverManager.getConnection(url, "jyuser", "beans") >>> stmt = con.createStatement() >>> con.autoCommit = 0 >>> try: ... # Insert an easy-to-find character for letter ... query = "INSERT INTO random (letter, number) VALUES ('.', 0)" ... stmt.executeUpdate(query) ... print "First update successful." ... stmt.execute("Create an exception here") ... con.commit() ... except: ... print "Error encountered, rolling back." ... con.rollback() ... 1 First update successful. Error encountered, rolling back. >>> >>> # now confirm that the first update statement was in fact undone >>> rs = stmt.executeQuery("SELECT * FROM random WHERE letter='.'") >>> rs.next() 0
The final zero at the end of the preceding example indicates that there is no result set for the query. This confirms that the first SQL insert statement was rolled back.
Working with JDBC from Jython is no doubt valuable. It allows prototyping in Jython and leverages JDBC skill sets; however, the numerous methods specific to Java types makes it clear that it is a Java API. Java, databases, and therefore JDBC are type-rich. The down side is that methods specific to Java native type are seemingly contrary to Jython's high-level, polymorphic dynamic types. In contrast, Python has a database API referred to as just the Python DB API, currently at version 2.0. Python's DB API 2.0 has been a standard API for interacting with databases from CPython; however, database drivers used by CPython are often useless to Jython because of underlying C implementations. Although Jython easily makes use of Java's database connectivity, it was still left wanting for a Java implementation of Python's DB API. Brian Zimmer, an avid Jython, Java, and Python developer, wrote zxJDBC to fill this void. In reality, zxJDBC does more that just implement the DB API, it also adds extensions to this API. Brian's zxJDBC tools are freely available, include source code, are well documentation, and are available at http://sf.net/projects/zxjdbc/ or http://www.ziclix.com/zxjdbc/. The zxJDBC tools may be incorporated into Jython proper by the time you read this, eliminating the need for a separate download. Check http://www.jython.org, or the Jython information at http://www.newriders.com/ for more information on this. If it isn't included in your version of Jython, you will need to download zxJDBC, and include the zxJDBC.jar file in your classpath. The zxJDBC package contains more tools than are shown here, including a package implementing the pipe pattern and the easy creation of datahandlers and DataHandlerFilters.
When you use the zxJDBC package, all that is required before calling the connection function is that zxJDBC.jar and the required JDBC driver exist in the classpath. The actual loading of the driver occurs behind the scenes when creating a connection to the database. The two steps to establishing a database connection with zxJDBC are as follows:
Include the appropriate driver and the zxJDBC.jar file in the classpath.
Supply a JDBC URL, username, password, and the name of the database Driver class to the zxJDBC.connect() method.
An appropriate classpath setting for using zxJDBC looks like this:
# For MySQL set CLASSPATH=mm_mysql-2_0_4-bin.jar;\path\to\zxJDBC.jar;%CLASSPATH% # For PostgreSQL set CLASSPATH=\path\to\jdbc7.1-1.2.jar;\path\to\zxJDBC.jar;%CLASSPATH%
The zxJDBC.connect method returns the database connection and has the following syntax:
zxJDBC.connect(URL, user, password, driver) -> connection
Retrieving the connection with the zxJDBC.connect method looks like this:
from com.ziclix.python.sql import zxJDBC mysqlConn = zxJDBC.connect("jdbc:mysql://localhost/test", "jyuser", "beans", "org.gjt.mm.mysql.Driver") postgresqlConn = zxJDBC.connect("jdbc:postgresql://localhost/test", "jyuser", "beans", "org.postgresql.Driver")
Special parameters required by drivers may appear as keyword arguments to the connect function. To set autoReconnect to true when connecting to a MySQL database include that parameter as a keyword argument as follows:
url = "jdbc:mysql://localhost/test" user = "jyuser" password = "beans" driver = "org.gjt.mm.mysql.Driver" mysqlConn = zxJDBC.connect(url, user, password, driver, autoReconnect="true")
Connection errors raise the exception DatabaseError, so handling errors with a connection attempt requires an except statement like the following:
url = "jdbc:mysql://localhost/test" user = "jyuser" password = "beans" driver = "org.gjt.mm.mysql.Driver" try: mysqlConn = zxJDBC.connect(url, user, password, driver, autoReconnect="true") except zxJDBC.DatabaseError: pass #handle error here
If you use a connection factory from the javax.sql package, or a class that implements javax.sql.DataSource or javax.sql.ConnectionPoolDataSource, you can connect with the zxJDBC.connectx method. Note that the javax.sql package is not included in the normal JDK installation, except for the enterprise version. The MySQL JDBC drive does, however, include the MysqlDataSource class used in the example below. The zxJDBC.connectx method requires the DataSource class and all the database connection parameters as keyword arguments, or as a dictionary object:
from com.ziclix.python.sql import zxJDBC userInfo = {'user':'jyuser', 'password':'beans'} con = zxJDBC.connectx("org.gjt.mm.mysql.MysqlDataSource", serverName='localhost', databaseName='test', port=3306, **userInfo)
The bean property names are set with keyword parameters in the preceding example, but could also be included in the dictionary containing the username and password information:
from com.ziclix.python.sql import zxJDBC userInfo = {'user':'jyuser', 'password':'beans', 'databaseName':'test', 'serverName':'localhost', 'port':3306} con = zxJDBC.connectx("org.gjt.mm.mysql.MysqlDataSource" , **userInfo)
You can also obtain a connection through a jndi lookup with the zxJDBC.lookup method. The lookup method only requires a string representing the JNDI name bound to the specific connection or DataSource you desire. Keyword parameters may be included and are converted to the static field values of javax.jndi.Context when the keywords match a Context's static field name.
A zxJDBC cursor is the object used to actually interact with the data in the database. A zxJDBC cursor is actually a wrapper around the JDBC Statement and ResultSet objects. The handling of the result sets is what differentiates the static and dynamic cursor types. A dynamic cursor is lazy. It iterates through the result set only as needed. This saves memory and evenly distributes processing time. A static cursor is not lazy. It iterates through the entire result set immediately, and incurs the memory overhead of doing so. The advantage of a static cursor is that you know the row count soon after executing a statement, something you cannot know when using a dynamic cursor. To get a cursor, call the zxJDBC connection object's cursor() method. An example of connecting to the database and retrieving a cursor object appears here:
from com.ziclix.python.sql import zxJDBC url = "jdbc:mysql://localhost/test" user = "jyuser" password = "beans" driver = "org.gjt.mm.mysql.Driver" con = zxJDBC.connect(url, user, password, driver, autoReconnect="true") cursor = con.cursor() # Static cursor # Alternatively, you can create a dynamic cursor cursor = con.cursor(1) # Optional boolean arg for dynamic
A cursor object's execute method executes SQL statements. The following example shows how to execute an SQL statement that selects all the data in the random table.
>>> from com.ziclix.python.sql import zxJDBC >>> url = "jdbc:mysql://localhost/test" >>> user, password, driver = "jyuser", "beans", "org.gjt.mm.mysql.Driver" >>> con = zxJDBC.connection(url, user, password, driver) >>> cursor = con.cursor() >>> cursor.execute("SELECT * FROM random")
To iterate through the results of a statement, you must use the cursor's fetchone, fetchmany, and fetchall methods. The fetchone and fetchall methods do exactly as their names imply, fetch one result set row, or fetch all rows. The fetchmany method accepts an optional argument which specifies the number of rows to return. Each time multiple rows are returned, they are returned as a sequence of sequences (list of tuples). You can see the usage of these three methods as the preceding example is continued:
>>> cursor.fetchone() (41, 'O', 1) >>> cursor.fetchmany() [(6, 'f', 2)] >>> cursor.fetchmany(4) [(49, 'W', 4), (35, 'I', 5), (43, 'Q', 6), (37, 'K', 3)] >>> cursor.fetchall() # All remaining in this case [(3, 'c', 7), (17, 'q', 8), (29, 'C', 9), (36, 'J', 10), (43, 'Q', 11), (23, 'w', 12), (49, 'W', 13), (25, 'y', 14), (40, 'N', 15), (50, 'X', 16), (46, 'T', 17), (51, 'Y', 18), (8, 'h', 19), (25, 'y', 20), (7, 'g', 21), (11, 'k', 22), (1, 'a', 23)]
After a query has been executed, you can view the row information for those rows in the result set with the cursor's description attribute. The description attribute is read-only, and contains a sequence for each row in the result set. Each sequence includes the name, type, display size, internal size, precision, scale, and nullable information for a column of the row set. A description of the previous query looks like this:
>>> cursor.description [('number', -6, 4, None, None, None, 1), ('letter', 1, 1, None, None, None, 1), ('pkey', 4, 10, None, 10, 0, 0)]
Table 11.3 shows the complete set of the cursor object's methods and attributes.
|
Method/Attribute |
Description |
|---|---|
|
description |
Information describing each column that appears in the results of a query. The information is a seven-item tuple containing name, type code, display size, internal size, precision, scale, and nullability. |
|
rowcount |
The number of rows in the results. This only works when the cursor is a static cursor, or after completely traversing the result set with a dynamic cursor. |
|
callproc(procedureName, [parameters]) |
Calls stored procedures and applies only to those databases that implement stored procedures. |
|
close() |
Closes the cursor. |
|
execute(statement) |
Executes a statement. |
|
executemany(statement, parameterList) |
Executes a statement with a parameter list. With this, you can use question marks in the statement for values and include a tuple of values to the parameterList which are replaced in the statement. |
|
fetchone() |
Retrieves one row of the query results. |
|
fetchmany([size]) |
Retrieves arraysize number of rows if no argument is given. If the argument arg is supplied, it returns arg numbers of result rows. |
|
fetchall() |
Retrieves all remaining result rows. |
|
nextset() |
Continues with the next result set.This applies only to those databases that support multiple result sets. |
|
arraysize |
The number of rows fetchmany() should return without arguments. |
The Python DB API does not contain metadata specifications, but zxJDBC does provide some connection metadata with a number of connection and cursor attributes. These attributes match bean properties found in the JDBC java.sql.DatabaseMetaData object discussed earlier in this chapter. Table 11.4 shows the zxJDBC cursor fields and the underlying DatabaseMetaData bean methods.
|
zxJDBC Attribute |
DatabaseMetaData Accessor |
|---|---|
|
connection.dbname |
getDatabaseProductName |
|
connection.dbversion |
getDatabaseProductVersion |
|
cursor.tables(catalog, schemapattern, tablepattern, types) |
getTables |
|
cursor.columns(catalog, schemapattern, tablenamepattern, columnnamepattern) |
getColumns |
|
cursor.foreignkeys(primarycatalog, primaryschema, pimarytable, foreigncatalog, foreignschema, foreigntable) |
getCrossReference |
|
cursor.primarykeys(catalog, schema, table) |
getPrimaryKeys |
|
cursor.procedures(catalog, schemapattern, procedurepattern) |
getProcedures |
|
cursor.procedurecolumns(catalog, schemapattern, procedurepattern, columnpattern) |
getProcedureColumns |
|
cursor.statistics(catalog, schema, table, unique, approximation) |
getIndexInfo |
Here is an example of extracting some metadata from the MySQL random database created earlier:
>>> from com.ziclix.python.sql import zxJDBC >>> url = "jdbc:mysql://localhost/test" >>> driver = "org.gjt.mm.mysql.Driver" >>> dbconn = zxJDBC.connect(url, "jyuser", "beans", driver) >>> dbconn.dbname 'MySQL' >>> dbconn.dbversion '3.23.32'
The remaining metadata is accessible through a cursor object. When the cursor retrieves information, it stores it internally waiting for the user to fetch it. To view metadata provided by the cursor, each metadata method must be called, then the cursor must be used to retrieve the data:
>>> cursor.primarykeys(None, "%", "random") >>> cursor.fetchall() [('', '', 'random', 'pkey', 1, 'pkey')] >>> cursor.tables(None, None, '%', None) >>> cursor.fetchall() [('', '', 'random', 'TABLE', '')] >>> cursor.primarykeys('test', '%', 'random') >>> cursor.fetchall() [('test', '', 'random', 'pkey', 1, 'pkey')] >>> cursor.statistics('test', '', 'random', 0, 1) >>> cursor.fetchall() [('test', '', 'random', 'false', '', 'PRIMARY', '3', 1, 'pkey', 'A', '23', None, '')]
The executemany() cursor method is the Python DB API Java's prepared statement. In reality, other statement executed are prepared, but the executemany() method allows you to use question marks for values in the SQL statement. The second argument to executemany() is a tuple of values that replaces the question marks in the SQL statement:
>>> sql = "INSERT INTO random (letter, number) VALUES (?, ?)" >>> cur.executemany(sql, ('Z', 51)) >>> >>> # view the row >>> cur.execute("SELECT * from random where letter='Z'") >>> cur.fetchall() [('Z', 51, 24)]
Exceptions that may be raised in zxJDBC are the following:
Error This is the generic exception.
DatabaseError Raised for database-specific errors. The connection object and all the connection methods (connect, lookup, conntectx) may raise this.
ProgrammingError Raised for coding errors such as missing parameters, bad SQL statements. The cursor object and the lookup connection may raise this.
NotSupportedError This exception is raised when a method is not implemented.
Each of these exceptions are within the zxJDBC package, so except clauses should look like the following:
>>> try: ... pass #Assume a method that raises and error is here ... except zxJDBC.DatabaseError: ... pass # Handle DatabaseError ... except zxJDBC.ProgrammingError: ... pass # handle ProgrammingError ... except notSupportedError: ... pass # handle not supported error ... except zxJDBC.Error: ... pass # Handle the generic Error exception
You can also get warnings with the cursor's warnings attribute. If no warnings exist, then use the cursor.warnings attribute in None.
Another extension available with the zxJDBC package is dbexts. dbexts is a Python module that adds another layer of abstraction around the Python DB API 2.0.With DBexts, you can specify connection information in a configuration file, and then use the higher-lever dbexts methods on the connections defined. In order to use dbexts, the dbexts.py module that comes with zxJDBC must be added to the sys.path. The configuration file can be any file, but the default is a file named dbexts.ini that resides in the same directory as the dbexts.py file. To use another file, include the filename in the dbexts constructor. Listing 11.4 is a configuration file that defines connections to the two databases used in this chapter.
[default] name=mysqltest [jdbc] name=mysqltest url=jdbc:mysql://localhost/test user=jyuser pwd=beans driver=org.gjt.mm.mysql.Driver [jdbc] name=pstest url=jdbc:postgresql://localhost/test user=jyuser pwd=beans driver=org.postgresql.Driver
Once the configuration file is defined, you can connect to the database by instantiating the dbexts class. In the following example, the dbexts.ini file is placed in the current working directory. You can alternatively place it in the directory on the sys.path where you placed the dbexts.py module:
>>> from dbexts import dbexts >>> mysqlcon = dbexts("mysqltest", "dbexts.ini") >>> psgrscon = dbexts("pstest", "dbexts.ini") >>> >>> # execute raw sql and get a list of headers and results >>> psgrscon.raw("SELECT * from random") ([('letter', 1, 1, None, None, None, 1), ('number', 4, 11, None, 10, 0, 1)], [('A', 4), ('f', 6), ('a', 1)]) >>> >>> # execute interactive sql >>> psgrscon.isql("select * from random") LETTER | NUMBER ---------------
A | 4 f | 6 a | 1 3 rows affected >>> >>> # Display schema- this works with postgresql, not MySQL >>> psgrscon.schema("random") Table random Primary Keys Imported (Foreign) Keys Columns letter bpchar(1), nullable number int4(4), nullable Indices >>> >>> # show tables in MySQL 'test' database >>> mysqlcon.table() TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS -----------------------------------------------------------
| | random | TABLE | 1 row affected
Table 11.5 lists the primary dbexts methods. Some of the methods have additional optional arguments and there are some additional methods, but they are bit beyond the scope of this chapter. For more details, consult the excellent documentation that comes with zxJDBC.
|
Method |
Description |
|---|---|
|
__init__(dbname, cfg, resultformatter, autocommit) |
The dbexts constructor. All parameters have default values, so they are all optional. The dbname is the name you specified for the connection in the dbexts.ini file. The cfg is the location of the dbexts.ini file if it does not reside in the same directory as the dbexts.py file. The resultformatter is a callable object that accepts a list of rows as one argument and optionally accepts a list of headers. The resultformatter object is called to display data. The autocommit argument is set to 1, or true, by default, but can be set to 0 if included in the call to the constructor. |
|
isql(sql, params, bindings, maxrows) |
The isql method interactively executes SQL statements. Interactive means that results are displayed with the resultformatter immediately after executing the statement, much like the MySQL and pSQL client programs. All parameters have default values except for the sql statement. The sql parameter is the SQL statement itself. The params parameter is a tuple of value parameters used to replace ? in SQL statements. The bindings parameter allows you to bind a datahandler. See the documentation on zxJDBC for more about datahandlers. The maxrows specifies the maximum number of rows to return, where zero or None means no limit. |
|
raw(sql, params, bindings) |
Executes the sql statement and returns a tuple containing headers and results. The params and bindings arguments are the same as for the isql method. |
|
schema(table, full, sort) |
Displays a table's indices, foreign keys, primary keys, and columns. If the full parameter is nonzero, the results include the table's referenced keys. A nonzero sort value means the table's column names will be sorted. |
|
table(table) |
The table parameter is optional. Without a table argument, this method displays a list of all tables. Otherwise, the specified table's columns are displayed. |
|
proc(proc) |
The proc parameter is optional. Without it, all procedures are listed. With it, the parameters for the specified procedure are displayed. |
|
bcp(src, table, where='(1=1)') |
This method copies data from specified database and table (src and table) to the current instance's database. |
|
begin(self) |
Creates a new cursor. |
|
rollback(self) |
Rolls back statements executed since the creation of a new cursor. |
|
commit(self, cursor=None, maxrows=None) |
Commits statements executed since the creation of a new cursor. |
|
display(self) |
Displays the results using the current formatter. |
|
CONTENTS | |