Aspects of Well-Designed Data Models
For an app in a tutorial, the data model is fairy substantive. However, it still doesn't encapsulate all of the functionality needed in a real banking app. You have necessarily limited its scope so that you can focus on concepts and not the intricacies of designing banking apps. This section will cover some of the more interesting aspects of data models.
Ghost Classes
One thing that you should notice about the Online Only Bank data model is that the AssetAccount class has no attributes or relationships (see Screenshot-1). The AssetAccount class is a special type of class called a ghost class. A ghost class marks a conceptual shift. In your data model, the OnlineCheckingAccount and SavingsAccount classes are both assets to your customers. On the other hand, the CreditCardAccount and LoanAccount classes are liabilities to your customer. Without a marker class separating assets from liabilities, all four of these classes would inherit from Account, removing the important distinction between assets and liabilities. By creating the ghost class AssetAccount, you gain much more flexibility, power, and long-term survivability in your data model. Since the OnlineCheckingAccount and SavingsAccount classes represent a conceptual difference between the other two accounts, you could conceive of a piece of logic that would have to make decisions based on this conceptual difference. For example, the officers of your bank may want to write a report of all the assets recorded for a particular customer. To complete this report, he would want to examine only the asset account objects. Of course, you may consider using a flag in each class, and letting the flag differentiate between assets and liabilities. However, placing a flag in the class signaling whether the class is an asset or a liability is the wrong approach because if you think of another category of accounts and want to implement it in later versions, a simple flag will not work. To fix this, you would have to go through all of the business logic and change the logic to account for the new account type. However, if your classes are conceptually divided with a ghost class, this work would be unnecessary. You would simply create a new ghost class for each new type of account, and the structure would be preserved. With this technique, the structure of the model itself is used to encapsulate information. Also, because AssetAccount represents a conceptual shift, it isn't difficult to imagine a subsequent requirement that would require a data member in the Asset class. Suppose six months down the line, your boss comes in and tells you to add a new attribute to the system. If you had used a flag instead of a ghost class, you now have a choice. Either you make some kind of sloppy kludge, or you refactor the data model to include an AssetAccount class. Either choice is not appealing. It's better simply to use a ghost class at the beginning and save yourself the trouble.
Proper Relationships
You may have noticed that inheritance was not used in the Customer and Employee classes to extend the Person class. This is because it is not warranted at this point. Many developers tend to use inheritance when aggregation would be more appropriate. In this case, a Person can assume the role of a Customer, an Employee, or both. In object-oriented engineering, there are three traditional questions that determine relationships between objects. The "is a," "has a," and "uses a" questions each define different relationships with different semantics. Using each kind of relationship properly is critical in creating a cohesive and stable data model.
Is a
The "is a" question determines inheritance. If you say that one object is another object, then you use inheritance. In the case of a SavingsAccount, you can say that a SavingsAccount is a type of AssetAccount. This relationship is shown in Screenshot-2.
Screenshot-2. Accounts in the Online Only Bank
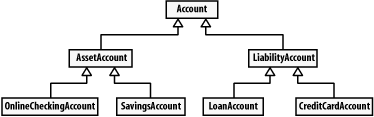
However, with the Customer class, the question gets tricky. You may say that a Customer is a Person; however, a Customer is not a type of Person. Instead, the Customer is one of many roles played by a Person; the Person is a part of the customer concept, so aggregation (see the next section) is required. If you change the traditional "is a" question to "is a type of," then the results become much clearer: a BankOfficer is a type of Employee but a Customer is not a type of Person. Using inheritance improperly is a common data-modeling mistake, one that can cause a number of undesirable side effects. For example, if you modeled Customer and Employee as inheriting from Person, then the same person could be in your system twice: for the employee of the company and when that person opens a new account. When you change the person's address, remember to change both instances of the person. This type of data duplication is just asking for bugs to be introduced into the system.
|

Has a
The "has a" question determines aggregation. If you say that one object has another object, then the object that has the other object aggregates it. For example, a customer has a person associated with it. Aggregation is really a special kind of association that models a relationship in which the object performing the aggregation is the whole, and the object that is aggregated is a part. This type of aggregation is often called shared aggregation because several classes can aggregate the aggregated class. For example, Person and Customer share an aggregation relationship because the person forms a part of the customer; furthermore, the person can also be an employee, which means the aggregation is shared. See Screenshot-3.
Screenshot-3. People in the Online Only Bank

There is also a special type of aggregation called composition, which occurs when an object aggregates another object and has life-cycle control over that object. For example, the HashMap class from uses an inner class called Entry to implement its storage buckets. These Entry objects can exist only within the context of a HashMap; they cannot exist on their own. See Screenshot-4.
Screenshot-4. A composition relationship
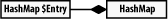
Composition also implies that only one class can compose an object; other classes can use it, but just one class can be its owner. In practice, composed objects are rarely shared but are isolated in private access. An Entry to a HashMap can be created only by the HashMap itself.
Uses a
The "uses a" question indicates plain association, in which a class can navigate to another class and use the services of that class. In association, the classes are conceptually on the same level. For example, a transaction uses an account and is therefore associated with it. However, Account and Transaction are on the same conceptual level, and neither is a part of the other, but you need to navigate between the two, so you use a plain association. See Screenshot-5.
Screenshot-5. A plain association
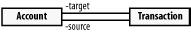
If you want more information on the concepts behind UML modeling, pick up a copy of The Unified Modeling Language User Guide by Booch, Rumbaugh, and Jacobson (Oracle).
A Primitive Question
Throughout the Online Only Bank data model, wrapper types are used for all primitives. No primitive objects are used in the model. This decision is rooted in a simple question, "How do you deal with null on a primitive field?" There are times when a value may be null in your data model without being an error. Consider the Transaction class. In this class, there is a Boolean indicating the success or failure of the transaction. However, if the transaction has not been submitted, this attribute could legally be null. If you wrote the class with primitives, the property methods would look like this:
public class Transaction {
public boolean successful;
public void setSuccessful(final boolean successful) {
this.successful = successful;
}
public boolean getSuccessful( ) {
return this.successful;
}
}
Since the success attribute in this example is a primitive, you cannot set its value to null. To compensate, you could state that transactions are failed until they succeed. However, this would give misleading information to your customers. They would log in to check their transaction list, find several failed transactions, and start to wonder why. On the other hand, if you use a wrapper type instead of a primitive, you would have the following code for your property:
public class Transaction {
public Boolean successful;
public void setSuccessful(final Boolean successful) {
this.successful = successful;
}
public Boolean getSuccessful( ) {
return this.successful;
}
}
In this case, you can legally set the value of successful as null. Since the property is a Boolean object, it can contain the value null. In this case, you can avoid the ambiguity of transactions that have not been submitted by setting their success to null. Throughout your data model, you need to decide whether to use primitives. One option is to use only wrapper types for the properties that can be null. A second option is to convert every primitive in the data model to their related wrapper classes.
Partial use of primitives
Using wrappers for only the attributes that can legally be null can save a small amount of memory per object. However, this extra memory is almost negligible unless you are storing thousands of numbers, in which case you would most likely use a complex data structure such as an array anyway. The array attribute can already contain null as a value. Also, using primitives for part of the data model cleans up the mathematics with the primitive variables:
public void calcMonthlyInterest(final LoanAccount loan) {
// -- Using Primitives float interest = loan.getBalance( ) * loan.getInterestRate( ); // -- Using Wrappers
float interest = loan.getBalance( ).floatValue( ) * loan.getInterestRate( ).floatValue( );
}
Primitive attributes also eliminate the need to create objects when calling a setter:
public void adjustLoan(final LoanAccount loan) {
// -- Using Primitives loan.setInterestRate(0.0565);
// -- Using Wrappers
loan.setInterestRate(new Float(0.0565));
}
Using only wrapper types
Using wrapper types for all primitives can clear up the semantics when dealing with the model. If you use only primitive wrappers, everything is an object. All getters return objects, and all setters take objects as arguments. This is convenient when dealing with reflection, as you will see in . Also, using primitive wrappers exclusively eliminates the need for many temporary objects, which would be required if the attribute was a primitive. For example, consider your basic bound property setter:
// -- Using Primitives public void setInterestRate(final float interestRate) {
float oldInterestRate = this.interestRate;
this. interestRate = interestRate;
propertyChangeSupport.firePropertyChange("interestRate ", new Float(interestRate), new Float(interestRate));
}
// -- Using Wrappers.
public void setInterestRate (final Float interestRate) {
Float oldInterestRate = this. interestRate;
this. interestRate = interestRate;
propertyChangeSupport.firePropertyChange("interestRate ", interestRate, interestRate);
}
You save two object instantiations per call by using a wrapped type; the instantiations are traded for one instantiation in the call to the setter. Since creating new objects on the heap is a relatively time-consuming task, avoiding it saves some CPU time. Even if there is a lot of math, the wrappers shouldn't affect performance. If you follow the principles of code efficiency, the difference between wrappers and primitives ceases to be an issue. Consider the following problematic example:
// -- Using Primitives public void doMath (final MyFactorObject obj) {
float result;
while(someCondition) {
result = result * obj.getFactor( );
}
}
// -- Using Wrappers.
public void doMath(final MyFactorObject obj) {
float result;
while(someCondition) {
result = result * obj.getFactor( ).floatValue( );
}
}
This common type of code shows the difference between using a wrapper and a primitive type. Whenever you iterate through the loop, you have to make an extra method call. However, this code is poorly designed. Calling a method that always returns the same result many times in the same method is bad practice. Calling a method that always returns the same result in a loop is even worse. With every iteration of the loop, you lose several clock cycles. To solve this problem, you can refactor the method:
// -- Using Primitives public void doMath (final MyFactorObject obj) {
float result;
float factor = obj.getFactor( );
while(someCondition) {
result = result * factor;
}
}
// -- Using Wrappers.
public void doMath(final MyFactorObject obj) {
float result;
float factor = obj.getFactor( ).floatValue( );
while(someCondition) {
result = result * factor; // <-- Speedy!!!
}
}
The difference between the two optimized methods is now only one call to floatValue( )—a fairly minor bit of overhead. You could eliminate this extra call by using primitives, but then you would lose all the advantages of these values being actual objects. When performing most math operations, there will be similar minor differences between using primitives and wrappers. Although you can save these minor amounts of overhead using primitives, you sacrifice consistency and flexibility in your data model. In the end, going with pure wrapper types has more advantages than disadvantages. The speed increase that primitives give you does not outweigh the clarity and flexibility of using wrappers. I suggest you use wrappers instead of primitives in data model objects.
Mutable Objects
In the data model, all of the objects fall under two categories. They are either constant objects, as in the case of Gender and LoanappStatus, or they are mutable data model objects, as in the case of Person and Account. The mutable objects in the model have much in common. Since they are all Java beans, and all of their properties are bound, they all need property change support for their events. Since they all need it, simply push this support into a base class called MutableObject, which is shown in Example 8-1.
Example 8-1. MutableObject
package oracle.hcj.datamodeling;
public abstract class MutableObject implements Serializable {
private static final transient Logger LOGGER = Logger.getLogger(MutableObject.class);
private static final long serialVersionUID = 7902971632143872731L;
protected final transient PropertyChangeSupport propertyChangeSupport =
new PropertyChangeSupport(this);
protected MutableObject( ) {
}
public void addPropertyChangeListener(
final PropertyChangeListener listener) {
propertyChangeSupport.addPropertyChangeListener(listener);
}
public void addPropertyChangeListener(final String property,
final PropertyChangeListener listener) {
propertyChangeSupport.addPropertyChangeListener(property, listener);
}
public void removePropertyChangeListener(
final PropertyChangeListener listener) {
propertyChangeSupport.removePropertyChangeListener(listener);
}
public void removePropertyChangeListener(final String property,
final PropertyChangeListener listener) {
propertyChangeSupport.removePropertyChangeListener(property, listener);
}
}
If you were developing software for a company, you would put MutableObject in a software common package so that other apps can use its services. The MutableObject class would form the base class for all of the data model objects. Throughout this tutorial, we will place more functionality into the MutableObject class to give your data models even more power.
Identity and equality for all objects
There is one other small problem in your data model. Recall from that the default implementation of the equals( ) method in java.lang.Object compares objects by identity rather than equality. Since you have not overridden the default method, you can't tell when one object is equivalent to another. This problem is easily solved by remembering to declare both an equals( ) and hashCode( ) method on all of the data objects or their superclasses, where appropriate. For example, you can declare that Account objects and all of their descendants use the ID property to compare for equivalence. Therefore, you can declare equals( ) and hashCode( ) methods in Account, which will apply to all descendants:
package oracle.hcj.bankdata;
public abstract class Account extends MutableObject {
/** * @see java.lang.Object#equals(java.lang.Object)
*/
public boolean equals(final Object obj) {
if (!(obj instanceof Account)) {
return false;
} else {
return (((Account)obj).getID( ).equals(this.ID));
}
}
/** * @see java.lang.Object#hashCode( )
*/
public int hashCode( ) {
return this.ID.hashCode( );
}
}
|

This will work for all of the account subtypes. Now you simply need to go through all the other data objects and repeat the process. However, if you forget to implement methods for one of your data objects, you would have a serious problem. Since the equals( ) and hashCode( ) methods are declared in Object, there would be no compiler error or warning. You may notice the problem only after you pull an all-night debugging session trying to figure out why your manager's reports don't include the loan accounts. Fortunately, there is a way to avoid this before it happens. One of the interesting and little known aspects of Java is that you can reabstract a method from a base class. As long as a method is not declared as final when you inherit the method in your class, you can add the keyword abstract to its declaration; this will force the users of your class to implement the method. You can alter MutableObject to reabstract equals( ) and hashCode( ):
package oracle.hcj.datamodeling;
public abstract class MutableObject implements Serializable {
public abstract boolean equals(Object obj);
public abstract int hashCode( );
}
Now that hashCode( ) and equals( ) are abstract, any class descending from MutableObject will have to implement these two methods somewhere along its class hierarchy. If the methods aren't declared, the compiler will object that the class needs to be declared as abstract. This trick is an invaluable tool in forcing descendants of a class to implement certain features.