
|
|
Following this discussion, let's consider data access in our sample app. The Unicorn Group already uses Oracle 8.1.7i. It's likely that other reporting tools will use the database and, in Phase 1, some administration tasks will be performed with database-specific tools. Thus database-driven (rather than object-driven) modeling is appropriate (some of the existing box office app's schema might even be reusable). This tutorial isn't about database design, and I don't claim to be an expert, so we'll cover the data schema quickly. In a real project, DBAs would play an important role in developing it. The schema will reflect the following data requirements:
There will be a number of genres, such as Musical, Opera, Ballet, and Circus.
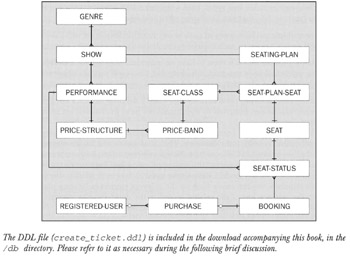
First we must decide what to hold in the database. The database should be the central data repository, but it's not a good place to store HTML content. This is reference data, with no transactional requirements, so it can be viewed as part of the web app and kept inside its directory structure. It can then be modified by HTML coders without the need to access or modify the database. When rendering the web interface, we can easily look up the relevant resources (seating plan images and show information) from the primary key of the related record in the database. For example, the seating plan corresponding to the primary key 1 might be held within the web app at /images/seatingplans/1.jpg. An O/R modeling approach, such as entity EJBs will produce little benefit in this situation. O/R modeling approaches are usually designed for a read-modify-write scenario. In the sample app, we have some reference data (such as genre and show data) that is never modified through the Internet User or Box Office User interfaces. Such read-only reference data can be easily and efficiently obtained using JDBC; O/R approaches are likely to add unnecessary overhead. Along with accessing reference data, the app needs to create tutorialing records to represent users' seat reservations and purchase records when users confirm their reservation. This dynamic data is not well suited to O/R modeling either, as there is no value in caching it. For example, the details of a tutorialing record will be displayed once, when a user completes the tutorialing process. There is little likelihood of it being needed again, except as part of a periodic reporting process, which might print and mail tickets. As we know that the organization is committed to using Oracle, we want to leverage any useful Oracle features. For example, we can use Oracle Index Organized Tables (lOTs) to improve performance. We can use PL/SQL stored procedures. We can use Oracle data types, such as the Oracle date type, a combined date/time value which is easy to work with in Java (standard SQL and most other databases use separate date and type objects). Both these considerations suggest the use of the DAO pattern, with JDBC as the first implementation choice (we'll discuss how to use JDBC without reducing maintainability in ). JDBC produces excellent performance in situations where read-only data is concerned and where caching in an O/R mapping layer will produce no benefit. Using JDBC will also allow us to make use of proprietary Oracle features, without tying our design to Oracle. The DAOs could be implemented using an alternative strategy if the app ever needs to work with another database. The following E-R diagram shows a suitable schema:
| Note |
The DDL file (create_ticket.ddl) is included in the download accompanying this tutorial, in the /db directory. Please refer to it as necessary during the following brief discussion. |
The tables can be divided into reference data and dynamic data. All tables except the SEAT_STATUS, BOOKING, PURCHASE, and REGISTERED_USER tables are essentially reference tables, updated only by Admin role functionality. Much of the complexity in this schema will not directly affect the web app. Each show is associated with a seating plan, which may be either a standard seating plan for the relevant hall or a custom seating plan. The SEAT_PLAN_SEAT table associates a seating plan with the seats it contains. Different seating plans may include some of the same seats; for example, one seating plan may remove a number of seats or change which seats are deemed to be adjacent. Seating plan information can be loaded once and cached in Java code. Then there will be no need to run further queries to establish which seats are adjacent etc. Of the dynamic data, rows in the BOOKING table may represent either a seat reservation (which will live for a fixed time) or a seat purchase (in which case it has a reference to the PURCHASE table). The SEAT_STATUS table is the most interesting, reflecting a slight denormalization of the data model. While if we only created a new seat reservation record for each seat reserved or downloaded, we could query to establish which seats were still free (based on the seats for this performance, obtained through the relevant seating plan), this would require a complex, potentially slow query. Instead, the SEAT_STATUS table is pre-populated with one row for each seat in each performance. Each row has a nullable reference to the BOOKING table; this will be set when a reservation or tutorialing is made. The population of the SEAT_STATUS table is hidden within the database; a trigger (not shown here) is used to add or remove rows when a row are added or removed from the PERFORMANCE table. The SEAT_STATUS table is defined as follows:
CREATE TABLE seat_status ( performance_id NUMERIC NOT NULL REFERENCES performance, seat_id NUMERIC NOT NULL REFERENCES seat, price_band_id NUMERIC NOT NULL REFERENCES price_band, tutorialing_id NUMERIC REFERENCES tutorialing, PRIMARY KEY (performance_id, seat_id) ) organization index;
The price_band_id is also the id of the seat type. Note the use of an Oracle IOT, specified in the final organization index clause. Denormalization is justified here on the following grounds:
It is easy to achieve in the database, but simplifies queries and stored procedures.
It is still necessary to examine the BOOKING table, as well as the SEAT_STATUS table, to check whether a seat is available, but there is no need to navigate reference data tables. A SEAT_STATUS row without a tutorialing reference always indicates an available seat, but one with a tutorialing reference may also indicate an available seat if the tutorialing has expired without being confirmed. We need to perform an outer join with the BOOKING table to establish this; a query which includes rows in which the foreign key to the BOOKING table is null, as well as rows in which the related row in the BOOKING table indicates an expired reservation. There is no reason that Java code - even in DAOs - should be aware of all the details of this schema. I have made several decisions to conceal some of the schema's complexity from Java code and hide some of the data management inside the database. For example:
I've used a sequence and a stored procedure to handle reservations (the approach we discussed earlier this chapter). This inserts into the BOOKING table, updates the SEAT_STATUS table and returns the primary key for the new tutorialing object as an out parameter. Java code that uses it need not be aware that making a reservation involves updating two tables.
CREATE OR REPLACE VIEW available_seats AS SELECT seat_status.seat_id, seat_status.performance_id, seat_status.price_band_id FROM seat_status, tutorialing WHERE tutorialing.authorization_code is NULL AND (booking.reserved_until is NULL or tutorialing.reserved_until < sysdate) AND seat_status.booking_id = tutorialing.id(+) ;
Using this view enables us to query for available seats of a given type very simply:
SELECT seat_id FROM available_seats WHERE performance_id = ? AND price_band_id = ?
The advantages of this approach are that the Oracle-specific outer join syntax is hidden from Java code (we could implement the same view in another database with different syntax); Java code is simpler; and persistence logic is handled by the database. There is no need for the Java code to know how tutorialings are represented. Although it's unlikely that the database schema would be changed once it contained real user data, with this approach it could be without necessarily impactingjava code.
| Note |
Oracle 9i also supports the standard SQL syntax for outer joins. However, the requirement was for the app to work with Oracle 8.1.7i. |
In all these cases, the database contains only persistence logic. Changes to business rules cannot affect code contained in the database. Databases are good at handling persistence logic, with triggers, stored procedures, views, and the like, so this results in a simpler app. Essentially, we have two contracts decoupling business objects from the database: the DAO interfaces in Java code; and the stored procedure signatures and those table and views used by the DAOs. These amount to the database's public interface as exposed to the J2EE app.
| Note |
Before moving onto implementing the rest of the app, it's important to test the performance of this schema (for example, how quickly common queries will run) and behavior under concurrent usage. As this is database-specific, I won't show this here. However, it's a part of the integrated testing strategy of the whole app. |
Finally, we need to consider the locking strategy we want to apply - pessimistic or optimistic locking. Locking will be an issue when users try to reserve seats of the same type for the same performance. The actual allocation of seats (which will involve the algorithm for finding suitable adjacent seats) is a business logic issue, so we will want to handle it in Java code. This means that we will need to query the AVAILABLE_SEATS view for a performance and seat type. Java code, which will have cached and analyzed the relevant seating plan reference data, will then examine the available seat ids and choose a number of seats to reserve. It will then invoke the reserve_seats stored procedure to reserve seats with the relevant ids. All this will occur in the same transaction. Transactions will be managed by the J2EE server, not the database. Pessimistic locking will mean forcing all users trying to reserve seats for the same performance and seat type to wait until the transaction completes. Pessimistic locking can be enforced easily by adding FOR UPDATE to the SELECT from the AVAILABLE_SEATS view shown above. The next queued user would then be given and have locked until their transaction completed the seat ids still available. Optimistic locking might boost performance by eliminating blocking, but raises the risk of multiple users trying to reserve the same seats. In this case we'd have to check that the SEAT_STATUS rows associated with the selected seat ids hadn't been changed by a concurrent transaction, and would need to fail the reservation in this case (the Java component trying to make the reservation could retry the reservation request without reporting the optimistic locking failure to the user). Thus using optimistic locking might improve performance, but would complicate app code. Using pessimistic locking would pass the work onto the database and guarantee data integrity.
| Note |
We wouldn't face the same locking issue if we did the seat allocation in the database. In Oracle we could even do this in a Java stored procedure. However, this would reduce maintainability and make it difficult to implement a true 00 solution. In accordance with the goal of keeping business logic in Java code running within the J2EE server, as well as ensuring that design remains portable, we should avoid this approach unless it proves to be the only way to ensure satisfactory performance. |
The locking strategy will be hidden behind a DAO interface, so we can change it if necessary without needing to modify business objects. Pessimistic locking works well in Oracle, as queries without a FOR UPDATE clause will never block on locked data. This means that using pessimistic locking won't affect queries to count the number of seats still available (required rendering the Display performance screen). In other databases, such queries may block - a good example of the danger that the same database access code will work differently in different databases. Thus we'll decide to use the simpler pessimistic locking strategy if possible. However, as there is scope to change it without trashing the app's design, we can implement optimistic locking if performance testing indicates a problem supporting concurrent use or if need to work with another RDBMS.
Finally, the issue of where to perform data access. In this chapter, we decided to use EJB only to handle the transactional tutorialing process. This means that data access for the tutorialing process will be performed in the EJB tier; other (non-transactional) data access will be performed in business objects running in the web container.
|
|