
|
|
Perhaps the most significant architectural decision is whether the app should be distributed, or whether all app components should be collocated on each server running the app. In some apps, business requirements dictate a distributed architectures. However, we often have a choice (for example, in many web apps). I believe that J2EE developers too often plump for distributed architectures, without giving this important choice sufficient thought. This is a potentially expensive mistake, as we shouldn't adopt a distributed architecture without good reason. In we considered the downside of distributed apps in complexity and performance Let's quickly review the major reasons why we might want to implement a distributed architecture:
To support J2EE technology clients such as Swing apps, providing them with a middle tier. A J2EE web container provides a middle tier for browser-based clients; hence this argument doesn't apply to apps with only a web interface.
| Note |
In rare cases, we might also choose to make an app distributed to introduce an additional firewall between web container and business objects. |
If the first or second criterion holds, a distributed architecture, based on EJB with remote interfaces, is the ideal – and simplest – solution. The issues around the third criterion are far more complex and seldom clear-cut. In the following section we'll look at them in more detail. This discussion assumes we're considering web apps (the commonest type of app in practice), and that RMI access isn't a decisive consideration.
Is a distributed architecture necessarily more scalable than one in which all components are collocated on each server? J2EE architects and developers tend to assume that distributed apps offer unmatched scalability. However, this assumption is questionable. Single-JVM solutions are higher-performing than distributed apps, due to the lack of remote invocation overhead, meaning that greater performance can be achieved on comparable hardware. Furthermore, single-JVM solutions can be clustered successfully. Enterprise-quality J2EE web containers provide clustering functionality; this is not the preserve of EJB containers. Alternatively, incoming HTTP requests can be routed to a server in a cluster by load balancing infrastructure provided to the J2EE server, or by hardware devices such as Cisco Load Balancer. (This looks like a single IP address, but in fact routes requests to any HTTP server behind it; it offers both, round robin and "sticky" routing, for cases when the client will need to go back to the same server to preserve session state). Using hardware load balancing has the advantage of working the same way with any J2EE server. By adding a tier of remote business objects (such as an EJB tier) we don't necessarily make a web app more scalable. A web app that doesn't require server-side state can scale linearly – almost indefinitely – regardless of whether it uses remote calling. When server-side state is required, scalability will be limited, regardless of whether we adopt a distributed model. If we hold state in the web tier (in the HttpSession object), the quality of the web container's clustering support (state replication and routing) will determine scalability. If we hold state in the EJB container, in stateful session beans, the EJB container will have a similarly difficult task. EJB is not a magic bullet that can make the problems of state replication go away. Plus we'll normally need to hold state in the web tier as well, unless we resort to the rare approach of serializing the stateful session bean handle into a cookie or hidden form field. A distributed J2EE app (in which business objects will be implemented as EJBs with remote interfaces) will be intrinsically more scalable than a single-JVM solution only when one or more of the following conditions hold:
The business objects accessed remotely are stateless, regardless of whether the web tier maintains state
In J2EE, this means that all business logic will be exposed by stateless session beans. Fortunately, this can often be arranged, as we'll see in . We discuss this type of architecture further below.
Scenarios in which there's a marked load disparity between web tier and business objects include the following:
Some or all of the business objects consume resources that cannot be allocated to every server in the web tier
In this rare scenario, collocating web tier and business objects means that we encounter the limitations of scalability of client-server apps. This scenario might arise if the app has an enormous load on the web tier and relatively little on the business objects. In this case, allowing each web container to allocate its own database connection pool, for example, might result in the database needing to support an excessively large number of connections.
A model with stateless business objects is highly scalable because we can add as many EJB containers as we need, without increasing the number of web containers or increasing the overhead of any state replication that may be required in the web tier. However, only in the event of a disparity in load between web tier and business objects will this approach be significantly more scalable than a web app in which all components are collocated on each server.
| Important |
A distributed app is not necessarily more scalable than one in which all components are collocated on each server. Only a distributed architecture with a stateful web tier and stateless business objects is inherently more scalable than a web app in which all components are collocated on each server. |
Is a distributed architecture necessarily more robust than one in which all components are collocated on a single server? Again, J2EE architects and developers tend to assume that it is. However, this assumption is also questionable. Any stateful app faces the problem of server affinity, in which users become associated with a particular server – a particular threat to robustness. Breaking an app into distributed units doesn't make this problem go away. If we have a stateless web tier, hardware routing can deliver brilliant uptime. Devices such as Cisco Load Balancer can detect when servers behind them go down and cease sending requests to them. The app's users will be shielded from such failures. If we maintain server-side state, it will need to be referenced by the web tier, which will become stateful. If we have a stateful web tier, the app, whether distributed or collocated, can only be as reliable as the web tier clustering technology. If a user is associated with one web tier server and it goes down, it won't matter if business objects on another server are still running. The user will encounter problems unless the session data was successfully replicated. By using stateful session beans, we merely move this problem to the EJB container, most often adding the problem of EJB tier replication to that of web tier replication, introducing the potential problem of server affinity (as we'll see in , stateful session beans are likely to be less, not more, robust in their handling of session state replication than HttpSession objects). Only if we have a stateful web tier but stateless business objects (stateless session EJBs in a J2EE app) is a distributed architecture likely to prove more robust (and scalable) than a collocated web app architecture. If the business objects can potentially cause serious failures, getting them "out of process" may deliver greater resilience, especially if the J2EE server offers sophisticated routing of stateless session bean calls. WebLogic, for example, can retry failed calls on stateless session beans to another server running the same EJB, if the failed method is marked as idempotent (not causing an update).
| Important |
A distributed architecture is not necessarily more robust than a collocated architecture. An architecture using stateless business objects is the only way to ensure that a distributed architecture is more robust – and more scalable – than a collocated architecture. |
The key determinant of the scalability and reliability of an architecture is whether it requires server-side state, rather than whether it is distributed. The following three architectures are likely to prove outstandingly robust and scalable (in descending order):
Stateless architecture, whether distributed or collocated
This offers unmatched scalability, performance, and reliability. Scalability can be delivered by hardware routing devices, and does not depend on sophisticated app server functionality. New servers can be added at will with no additional performance overhead. Resources outside the J2EE app, such as databases, will usually limit scalability. A surprisingly large proportion of web apps can be made to be stateless, especially if it's possible to use cookies.
However, if the web container does need to maintain session state, it's a different story. By removing the business objects from the servers running the web tier, we may be able to improve web throughput while keeping the overhead of session state replication to a minimum. We can increase overall throughput by adding more EJB containers running stateless session bean business objects. There will be some overhead in scaling up, as the app server will need to manage routing within the cluster, but as no session state replication will be required, such overhead will be modest.
Distributed architectures with stateful business objects (such as stateful session beans) are likely to prove less scalable than any of these, more complex to deploy, and less performant.
| Important |
When we need to hold session state, distributed architectures with stateless business objects can deliver the ultimate in J2EE scalability and reliability, at the cost of a performance overhead and degree of complexity that is unnecessary in most apps. |
The following diagram illustrates such a scalable and robust distributed J2EE architecture. Since business logic is implemented using stateless session beans (SLSB) with remote interfaces, it is possible to run more EJB containers than web containers. In this architecture, adding an EJB container adds lesser overhead than adding a web container, because session state replication is required between web containers:
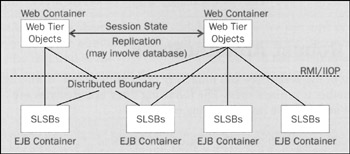
It's important to note that the overhead of adding a new web container to a cluster, where state replication is involved, will differ between servers and with the replication strategy used. I'm assuming the use of in-memory replication, in which replicated session data is exchanged between servers in a cluster, but never stored in a database (replication in which a backing store is involved will theoretically scale up almost linearly, but imposes a massive performance overhead, and may encounter problems if a subsequent load-balanced request is received before session data has been stored – a real possibility, as writing to a persistent store is likely to be a slow operation; hence it's usually impracticable). In servers such as WebLogic, which use a single, randomly selected, secondary server to which session state is replicated with every request, the overhead in adding more servers may be modest (at the cost of the possibility of both primary and secondary servers failing at once). In servers such as Tomcat, in which session state is replicated to all servers in a cluster, there will be an effective limit on the number of servers that can efficiently function in a cluster without replication overwhelming the LAN and accounting for most of the servers' workload (the benefit being a potential increase in overall resilience). In my experience, the following principles help to achieve maximum scalability and reliability in web apps:
Avoid holding server-side session state if possible
The sample app's requirements do not call for RMI access to business objects. If remote access is required in future, it's more likely to call for an XML-based web services approach. So we have a choice as to whether to use a distributed architecture, and whether EJBs with remote interfaces are required. The sample app does require server-side session state. Server-side session state, such as a seat reservation held by the user, is so important to the sample app's workflow that trying to evade it by using hidden form fields and the like will prove extremely complex, and a rich source of bugs. We could attempt to hold the user's session state in the database, but this would impact performance even if we weren't running in a cluster (the app initially will run on a single server), and would complicate the app by the need to hold a session key in a cookie or a hidden form field. In this app, it was a business requirement that Internet users were not required to accept cookies (this often isn't the case; if cookies are permissible, there may be alternatives to server-side session state). We should ensure that the amount of server-side state is kept to the minimum, and that any objects placed in the user's HttpSession are serializable efficiently. We should also avoid the temptation to hold all session data in one large object, but put separate objects in the HttpSession. For example, seat reservation and user profile objects can be held separately, so that if only one changes, the web container does not need to replicate the data for both. We will take care to ensure that we don't include shared data in individual user sessions. For example, we will include the numeric primary key of a performance for which a user has reserved, rather than the shared reference data object representing the performance itself. As performance objects are part of a large object graph, which would need to be serialized in its entirety, this is a potentially huge saving if the app ever runs in a cluster. Such replacement of an object with a lookup key is a common and highly effective technique for reducing the volume of session state that must be maintained for each user. In the sample app, it's unlikely that the business objects will prove to be a bottleneck. We can simply add new servers running the whole app – including the web tier – to scale up. Hence there is no benefit in using a distributed architecture, even with stateless business objects.
Thus we adopt the third architecture discussed above: web app with all components collocated on each server. Not only will this prove scalable and reliable enough to satisfy our requirements, it will also maximize performance and minimize overhead (the business requirements stressed that performance should be maximized per unit hardware).
|
|