Excluding Robots
The robot community understood the problems that robotic web site access could cause. In 1994, a simple, voluntary technique was proposed to keep robots out of where they don't belong and provide webmasters with a mechanism to better control their behavior. The standard was named the "Robots Exclusion Standard" but is often just called robots.txt, after the file where the access-control information is stored.
The idea of robots.txt is simple. Any web server can provide an optional file named robots.txt in the document root of the server. This file contains information about what robots can access what parts of the server. If a robot follows this voluntary standard, it will request the robots.txt file from the web site before accessing any other resource from that site. For example, the robot in Screenshot 9-6 wants to download http://www.joes-hardware.com/specials/acetylene-torches.html from Joe's Hardware. Before the robot can request the page, however, it needs to check the robots.txt file to see if it has permission to fetch this page. In this example, the robots.txt file does not block the robot, so the robot fetches the page.

(Screenshot 9-6.)
The Robots Exclusion Standard
The Robots Exclusion Standard is an ad hoc standard. At the time of this writing, no official standards body owns this standard, and vendors implement different subsets of the standard. Still, some ability to manage robots' access to web sites, even if imperfect, is better than none at all, and most major vendors and search-engine crawlers implement support for the exclusion standard.
There are three revisions of the Robots Exclusion Standard, though the naming of the versions is not well defined. We adopt the version numbering shown in Table 9-2.
Table 9-2. Robots Exclusion Standard versions | ||
| Version | Title and description | Date |
| 0.0 | A Standard for Robot Exclusion-Martijn Koster's original robots.txt mechanism with Disallow directive | June 1994 |
| 1.0 | A Method for Web Robots Control-Martijn Koster's IETF draft with additional support for Allow | Nov. 1996 |
| 2.0 | An Extended Standard for Robot Exclusion-Sean Conner's extension including regex and timing information; not widely supported | Nov. 1996 |
Most robots today adopt the v0.0 or v1.0 standards. The v2.0 standard is much more complicated and hasn't been widely adopted. It may never be. We'll focus on the v1.0 standard here, because it is in wide use and is fully compatible with v0.0.
Web Sites and robots.txt Files
Before visiting any URLs on a web site, a robot must retrieve and process the robots.txt file on the web site, if it is present. There is a single robots.txt resource for the entire web site defined by the hostname and port number. If the site is virtually hosted, there can be a different robots.txt file for each virtual docroot, as with any other file.
Even though we say "robots.txt file," there is no reason that the robots.txt resource must strictly reside in a filesystem. For example, the robots.txt resource could by dynamically generated by a gateway application.
Currently, there is no way to install "local" robots.txt files in individual subdirectories of a web site. The webmaster is responsible for creating an aggregate robots.txt file that describes the exclusion rules for all content on the web site.
Fetching robots.txt
Robots fetch the robots.txt resource using the HTTP GET method, like any other file on the web server. The server returns the robots.txt file, if present, in a text/plain body. If the server responds with a 404 Not Found HTTP status code, the robot can assume that there are no robotic access restrictions and that it can request any file.
Robots should pass along identifying information in the From and User-Agent headers to help site administrators track robotic accesses and to provide contact information in the event that the site administrator needs to inquire or complain about the robot. Here's an example HTTP crawler request from a commercial web robot:
GET /robots.txt HTTP/1.0
Host: www.joes-hardware.com
User-Agent: Slurp/2.0
Date: Wed Oct 3 20:22:48 EST 2001
Response codes
Many web sites do not have a robots.txt resource, but the robot doesn't know that. It must attempt to get the robots.txt resource from every site. The robot takes different actions depending on the result of the robots.txt retrieval:
· If the server responds with a success status (HTTP status code 2XX), the robot must parse the content and apply the exclusion rules to fetches from that site.
· If the server response indicates the resource does not exist (HTTP status code 404), the robot can assume that no exclusion rules are active and that access to the site is not restricted by robots.txt.
· If the server response indicates access restrictions (HTTP status code 401 or 403) the robot should regard access to the site as completely restricted.
· If the request attempt results in temporary failure (HTTP status code 503), the robot should defer visits to the site until the resource can be retrieved.
· If the server response indicates redirection (HTTP status code 3XX), the robot should follow the redirects until the resource is found.
robots.txt File Format
The robots.txt file has a very simple, line-oriented syntax. There are three types of lines in a robots.txt file: blank lines, comment lines, and rule lines. Rule lines look like HTTP headers (<Field>: <value>) and are used for pattern matching. For example:
# this robots.txt file allows Slurp & Webcrawler to crawl
# the public parts of our site, but no other robots...
User-Agent: slurp
User-Agent: webcrawler
Disallow: /private
User-Agent: *
Disallow:
The lines in a robots.txt file are logically separated into "records." Each record describes a set of exclusion rules for a particular set of robots. This way, different exclusion rules can be applied to different robots.
Each record consists of a set of rule lines, terminated by a blank line or end-of-file character. A record starts with one or more User-Agent lines, specifying which robots are affected by this record, followed by Disallow and Allow lines that say what URLs these robots can access.
For practical reasons, robot software should be robust and flexible with the end-of-line character. CR, LF, and CRLF should all be supported.
The previous example shows a robots.txt file that allows the Slurp and Webcrawler robots to access any file except those files in the private subdirectory. The same file also prevents any other robots from accessing anything on the site.
Let's look at the User-Agent, Disallow, and Allow lines.
The User-Agent line
Each robots record starts with one or more User-Agent lines, of the form:
User-Agent: <robot-name>
or:
User-Agent: *
The robot name (chosen by the robot implementor) is sent in the User-Agent header of the robot's HTTP GET request.
When a robot processes a robots.txt file, it must obey the record with either:
· The first robot name that is a case-insensitive substring of the robot's name
· The first robot name that is "*"
If the robot can't find a User-Agent line that matches its name, and can't find a wildcarded "User-Agent: *" line, no record matches, and access is unlimited.
Because the robot name matches case-insensitive substrings, be careful about false matches. For example, "User-Agent: bot" matches all the robots named Bot, Robot, Bottom-Feeder, Spambot, and Dont-Bother-Me.
The Disallow and Allow lines
The Disallow and Allow lines immediately follow the User-Agent lines of a robot exclusion record. They describe which URL paths are explicitly forbidden or explicitly allowed for the specified robots.
The robot must match the desired URL against all of the Disallow and Allow rules for the exclusion record, in order. The first match found is used. If no match is found, the URL is allowed.
The robots.txt URL always is allowed and must not appear in the Allow/Disallow rules.
For an Allow/Disallow line to match a URL, the rule path must be a case-sensitive prefix of the URL path. For example, "Disallow: /tmp" matches all of these URLs:
http://www.joes-hardware.com/tmp
http://www.joes-hardware.com/tmp/
http://www.joes-hardware.com/tmp/pliers.html
http://www.joes-hardware.com/tmpspc/stuff.txt
Disallow/Allow prefix matching
Here are a few more details about Disallow/Allow prefix matching:
· Disallow and Allow rules require case-sensitive prefix matches. The asterisk has no special meaning (unlike in User-Agent lines), but the universal wildcarding effect can be obtained from the empty string.
· Any "escaped" characters (%XX) in the rule path or the URL path are unescaped back into bytes before comparison (with the exception of %2F, the forward slash, which must match exactly).
· If the rule path is the empty string, it matches everything.
Table 9-3 lists several examples of matching between rule paths and URL paths.
Table 9-3. Robots.txt path matching examples | |||
| Rule path | URL path | Match? | Comments |
| /tmp | /tmp | 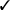
| Rule path == URL path |
| /tmp | /tmpfile.html |
| Rule path is a prefix of URL path |
| /tmp | /tmp/a.html |
| Rule path is a prefix of URL path |
| /tmp/ | /tmp | X | /tmp/ is not a prefix of /tmp |
| README.TXT |
| Empty rule path matches everything | |
| /~fred/hi.html | %7Efred/hi.html |
| %7E is treated the same as ~ |
| /%7Efred/hi.html | /~fred/hi.html |
| %7E is treated the same as ~ |
| /%7efred/hi.html | /%7Efred/hi.html |
| Case isn't significant in escapes |
| /~fred/hi.html | ~fred%2Fhi.html | X | %2F is slash, but slash is a special case that must match exactly |
Prefix matching usually works pretty well, but there are a few places where it is not expressive enough. If there are particular subdirectories for which you also want to disallow crawling, regardless of what the prefix of the path is, robots.txt provides no means for this. For example, you might want to avoid crawling of RCS version control subdirectories. Version 1.0 of the robots.txt scheme provides no way to support this, other than separately enumerating every path to every RCS subdirectory.
Other robots.txt Wisdom
Here are some other rules with respect to parsing the robots.txt file:
· The robots.txt file may contain fields other than User-Agent, Disallow, and Allow, as the specification evolves. A robot should ignore any field it doesn't understand.
· For backward compatibility, breaking of lines is not allowed.
· Comments are allowed anywhere in the file; they consist of optional whitespace, followed by a comment character (#) followed by the comment, until the end-of-line character.
· Version 0.0 of the Robots Exclusion Standard didn't support the Allow line. Some robots implement only the Version 0.0 specification and ignore Allow lines. In this situation, a robot will behave conservatively, not retrieving URLs that are permitted.
Caching and Expiration of robots.txt
If a robot had to refetch a robots.txt file before every file access, it would double the load on web servers, as well as making the robot less efficient. Instead, robots are expected to fetch the robots.txt file periodically and cache the results. The cached copy of robots.txt should be used by the robot until the robots.txt file expires. Standard HTTP cache-control mechanisms are used by both the origin server and robots to control the caching of the robots.txt file. Robots should take note of Cache-Control and Expires headers in the HTTP response.
See Section 7.8 for more on handling caching directives.
Many production crawlers today are not HTTP/1.1 clients; webmasters should note that those crawlers will not necessarily understand the caching directives provided for the robots.txt resource.
If no Cache-Control directives are present, the draft specification allows caching for seven days. But, in practice, this often is too long. Web server administrators who did not know about robots.txt often create one in response to a robotic visit, but if the lack of a robots.txt file is cached for a week, the newly created robots.txt file will appear to have no effect, and the site administrator will accuse the robot administrator of not adhering to the Robots Exclusion Standard.
Several large-scale web crawlers use the rule of refetching robots.txt daily when actively crawling the Web.
Robot Exclusion Perl Code
A few publicly available Perl libraries exist to interact with robots.txt files. One example is the WWW::RobotsRules module available for the CPAN public Perl archive.
The parsed robots.txt file is kept in the WWW::RobotRules object, which provides methods to check if access to a given URL is prohibited. The same WWW::RobotRules object can parse multiple robots.txt files.
Here are the primary methods in the WWW::RobotRules API:
Create RobotRules object
$rules = WWW::RobotRules->new($robot_name);
Load the robots.txt file
$rules->parse($url, $content, $fresh_until);
Check if a site URL is fetchable
$can_fetch = $rules->allowed($url);
Here's a short Perl program that demonstrates the use of WWW::RobotRules:
require WWW::RobotRules;
# Create the RobotRules object, naming the robot "SuperRobot"
my $robotsrules = new WWW::RobotRules 'SuperRobot/1.0';
use LWP::Simple qw(get);
# Get and parse the robots.txt file for Joe's Hardware, accumulating the rules
$url = "http://www.joes-hardware.com/robots.txt";
my $robots_txt = get $url;
$robotsrules->parse($url, $robots_txt);
# Get and parse the robots.txt file for Mary's Antiques, accumulating the rules
$url = "http://www.marys-antiques.com/robots.txt";
my $robots_txt = get $url;
$robotsrules->parse($url, $robots_txt);
# Now RobotRules contains the set of robot exclusion rules for several
# different sites. It keeps them all separate. Now we can use RobotRules
# to test if a robot is allowed to access various URLs.
if ($robotsrules->allowed($some_target_url))
{
$c = get $url;
...
}
The following is a hypothetical robots.txt file for www.marys-antiques.com:
#####################################################################
# This is the robots.txt file for Mary's Antiques web site
#####################################################################
# Keep Suzy's robot out of all the dynamic URLs because it doesn't
# understand them, and out of all the private data, except for the
# small section Mary has reserved on the site for Suzy.
User-Agent: Suzy-Spider
Disallow: /dynamic
Allow: /private/suzy-stuff
Disallow: /private
# The Furniture-Finder robot was specially designed to understand
# Mary's antique store's furniture inventory program, so let it
# crawl that resource, but keep it out of all the other dynamic
# resources and out of all the private data.
User-Agent: Furniture-Finder
Allow: /dynamic/check-inventory
Disallow: /dynamic
Disallow: /private
# Keep everyone else out of the dynamic gateways and private data.
User-Agent: *
Disallow: /dynamic
Disallow: /private
This robots.txt file contains a record for the robot called SuzySpider, a record for the robot called FurnitureFinder, and a default record for all other robots. Each record applies a different set of access policies to the different robots:
· The exclusion record for SuzySpider keeps the robot from crawling the store inventory gateway URLs that start with /dynamic and out of the private user data, except for the section reserved for Suzy.
· The record for the FurnitureFinder robot permits the robot to crawl the furniture inventory gateway URL. Perhaps this robot understands the format and rules of Mary's gateway.
· All other robots are kept out of all the dynamic and private web pages, though they can crawl the remainder of the URLs.
Table 9-4 lists some examples for different robot accessibility to the Mary's Antiques web site.
Table 9-4. Robot accessibility to the Mary's Antiques web site | |||
| URL | SuzySpider | FurnitureFinder | NosyBot |
| http://www.marys-antiques.com/ |
|
|
|
| http://www.marys-antiques.com/index.html |
|
|
|
| http://www.marys-antiques.com/private/payroll.xls | X | X | X |
| http://www.marys-antiques.com/private/suzy-stuff/taxes.txt |
| X | X |
| http://www.marys-antiques.com/dynamic/buy-stuff?id=3546 | X | X | X |
| http://www.marys-antiques.com/dynamic/check-inventory?kitchen | X |
| X |
HTML Robot-Control META Tags
The robots.txt file allows a site administrator to exclude robots from some or all of a web site. One of the disadvantages of the robots.txt file is that it is owned by the web site administrator, not the author of the individual content.
HTML page authors have a more direct way of restricting robots from individual pages. They can add robot-control tags to the HTML documents directly. Robots that adhere to the robot-control HTML tags will still be able to fetch the documents, but if a robot exclusion tag is present, they will disregard the documents. For example, an Internet search-engine robot would not include the document in its search index. As with the robots.txt standard, participation is encouraged but not enforced.
Robot exclusion tags are implemented using HTML META tags, using the form:
<META NAME="ROBOTS" CONTENT=directive-list>
Robot META directives
There are several types of robot META directives, and new directives are likely to be added over time and as search engines and their robots expand their activities and feature sets. The two most-often-used robot META directives are:
NOINDEX
Tells a robot not to process the page's content and to disregard the document (i.e., not include the content in any index or database).
<META NAME="ROBOTS" CONTENT="NOINDEX">
NOFOLLOW
Tells a robot not to crawl any outgoing links from the page.
<META NAME="ROBOTS" CONTENT="NOFOLLOW">
In addition to NOINDEX and NOFOLLOW, there are the opposite INDEX and FOLLOW directives, the NOARCHIVE directive, and the ALL and NONE directives. These robot META tag directives are summarized as follows:
INDEX
Tells a robot that it may index the contents of the page.
FOLLOW
Tells a robot that it may crawl any outgoing links in the page.
NOARCHIVE
Tells a robot that it should not cache a local copy of the page.
This META tag was introduced by the folks who run the Google search engine as a way for webmasters to opt out of allowing Google to serve cached pages of their content. It also can be used with META NAME="googlebot".
ALL
Equivalent to INDEX, FOLLOW.
NONE
Equivalent to NOINDEX, NOFOLLOW.
The robot META tags, like all HTML META tags, must appear in the HEAD section of an HTML page:
<html>
<head>
<meta name="robots" content="noindex,nofollow">
<title>...</title>
</head>
<body>
...
</body>
</html>
Note that the "robots" name of the tag and the content are case-insensitive.
You obviously should not specify conflicting or repeating directives, such as:
<meta name="robots" content="INDEX,NOINDEX,NOFOLLOW,FOLLOW,FOLLOW">
the behavior of which likely is undefined and certainly will vary from robot implementation to robot implementation.
Search engine META tags
We just discussed robots META tags, used to control the crawling and indexing activity of web robots. All robots META tags contain the name="robots" attribute.
Many other types of META tags are available, including those shown in Table 9-5. The DESCRIPTION and KEYWORDS META tags are useful for content-indexing search-engine robots.
Table 9-5. Additional META tag directives | ||
| name= | content= | Description |
| DESCRIPTION | <text> | Allows an author to define a short text summary of the web page. Many search engines look at META DESCRIPTION tags, allowing page authors to specify appropriate short abstracts to describe their web pages.
<meta name="description" content="Welcome to Mary's Antiques web site"> |
| KEYWORDS | <comma list> | Associates a comma-separated list of words that describe the web page, to assist in keyword searches.
<meta name="keywords" content="antiques,mary,furniture,restoration"> |
| REVISIT-AFTER | <no. days> | Instructs the robot or search engine that the page should be revisited, presumably because it is subject to change, after the specified number of days.
<meta name="revisit-after" content="10 days"> |
This directive is not likely to have wide support.