Character Sets and HTTP
So, let's jump right into the most important (and confusing) aspects of web internationalization-international alphabetic scripts and their character set encodings.
Web character set standards can be pretty confusing. Lots of people get frustrated when they first try to write international web software, because of complex and inconsistent terminology, standards documents that you have to pay to read, and unfamiliarity with foreign languages. This section and the next section should make it easier for you to use character sets with HTTP.
Charset Is a Character-to-Bits Encoding
The HTTP charset values tell you how to convert from entity content bits into characters in a particular alphabet. Each charset tag names an algorithm to translate bits to characters (and vice versa). The charset tags are standardized in the MIME character set registry, maintained by the IANA (see http://www.isi.edu/in-notes/iana/assignments/character-sets). Appendix H summarizes many of them.
The following Content-Type header tells the receiver that the content is an HTML file, and the charset parameter tells the receiver to use the iso-8859-6 Arabic character set decoding scheme to decode the content bits into characters:
Content-Type: text/html; charset=iso-8859-6
The iso-8859-6 encoding scheme maps 8-bit values into both the Latin and Arabic alphabets, including numerals, punctuation and other symbols. For example, in Screenshot 16-1, the highlighted bit pattern has code value 225, which (under iso-8859-6) maps into the Arabic letter "FEH" (a sound like the English letter "F").
Unlike Chinese and Japanese, Arabic has only 28 characters. Eight bits provides 256 unique values, which gives plenty of room for Latin characters, Arabic characters, and other useful symbols.

(Screenshot 16-1.)
Some character encodings (e.g., UTF-8 and iso-2022-jp) are more complicated, variable-length codes, where the number of bits per character varies. This type of coding lets you use extra bits to support alphabets with large numbers of characters (such as Chinese and Japanese), while using fewer bits to support standard Latin characters.
How Character Sets and Encodings Work
Let's see what character sets and encodings really do.
We want to convert from bits in a document into characters that we can display onscreen. But because there are many different alphabets, and many different ways of encoding characters into bits (each with advantages and disadvantages), we need a standard way to describe and apply the bits-to-character decoding algorithm.
Bits-to-character conversions happen in two steps, as shown in Screenshot 16-2:
· In Screenshot 16-2a, bits from a document are converted into a character code that identifies a particular numbered character in a particular coded character set. In the example, the decoded character code is numbered 225.
· In Screenshot 16-2b, the character code is used to select a particular element of the coded character set. In iso-8859-6, the value 225 corresponds to "ARABIC LETTER FEH." The algorithms used in Steps a and b are determined from the MIME charset tag.

(Screenshot 16-2.)
A key goal of internationalized character systems is the isolation of the semantics (letters) from the presentation (graphical presentation forms). HTTP concerns itself only with transporting the character data and the associated language and charset labels. The presentation of the character shapes is handled by the user's graphics display software (browser, operating system, fonts), as shown in Screenshot 16-2c.
The Wrong Charset Gives the Wrong Characters
If the client uses the wrong charset parameter, the client will display strange, bogus characters. Let's say a browser got the value 225 (binary 11100001) from the body:
· If the browser thinks the body is encoded with iso-8859-1 Western European character codes, it will show a lowercase Latin "a" with acute accent:
á
· If the browser is using iso-8859-6 Arabic codes, it will show "FEH":
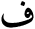
· If the browser is using iso-8859-7 Greek, it will show a small "Alpha":

· If the browser is using iso-8859-8 Hebrew codes, it will show "BET":
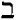
Standardized MIME Charset Values
The combination of a particular character encoding and a particular coded character set is called a MIME charset. HTTP uses standardized MIME charset tags in the Content-Type and Accept-Charset headers. MIME charset values are registered with the IANA. Table 16-1 lists a few MIME charset encoding schemes used by documents and browsers. A more complete list is provided in Appendix H.
See http://www.iana.org/numbers.htm for the list of registered charset values.
Table 16-1. MIME charset encoding tags | |
| MIME charset value | Description |
| us-ascii | The famous character encoding standardized in 1968 as ANSI_X3.4-1968. It is also named ASCII, but the "US" prefix is preferred because of several international variants in ISO 646 that modify selected characters. US-ASCII maps 7-bit values into 128 characters. The high bit is unused. |
| iso-8859-1 | iso-8859-1 is an 8-bit extension to ASCII to support Western European languages. It uses the high bit to include many West European characters, while leaving the ASCII codes (0-127) intact. Also called iso-latin-1, or nicknamed "Latin1." |
| iso-8859-2 | Extends ASCII to include characters for Central and Eastern European languages, including Czech, Polish, and Romanian. Also called iso-latin-2. |
| iso-8859-5 | Extends ASCII to include Cyrillic characters, for languages including Russian, Serbian, and Bulgarian. |
| iso-8859-6 | Extends ASCII to include Arabic characters. Because the shapes of Arabic characters change depending on their position in a word, Arabic requires a display engine that analyzes the context and generates the correct shape for each character. |
| iso-8859-7 | Extends ASCII to include modern Greek characters. Formerly known as ELOT-928 or ECMA-118:1986. |
| iso-8859-8 | Extends ASCII to include Hebrew and Yiddish characters. |
| iso-8859-15 | Updates iso-8859-1, replacing some less-needed punctuation and fraction symbols with forgotten French and Finnish letters and replacing the international currency sign with the symbol for the new Euro currency. This character set is nicknamed "Latin0" and may one day replace iso-8859-1 as the preferred default character set in Europe. |
| iso-2022-jp | iso-2022-jp is a widely used encoding for Japanese email and web content. It is a variable-length encoding scheme that supports ASCII characters with single bytes but uses three-character modal escape sequences to shift into three different Japanese character sets. |
| euc-jp | euc-jp is an ISO 2022-compliant variable-length encoding that uses explicit bit patterns to identify each character, without requiring modes and escape sequences. It uses 1-byte, 2-byte, and 3-byte sequences of characters to identify characters in multiple Japanese character sets. |
| Shift_JIS | This encoding was originally developed by Microsoft and sometimes is called SJIS or MS Kanji. It is a bit complicated, for reasons of historic compatibility, and it cannot map all characters, but it still is common. |
| koi8-r | KOI8-R is a popular 8-bit Internet character set encoding for Russian, defined in IETF RFC 1489. The initials are transliterations of the acronym for "Code for Information Exchange, 8 bit, Russian." |
| utf-8 | UTF-8 is a common variable-length character encoding scheme for representing UCS (Unicode), which is the Universal Character Set of the world's characters. UTF-8 uses a variable-length encoding for character code values, representing each character by from one to six bytes. One of the primary features of UTF-8 is backward compatibility with ordinary 7-bit ASCII text. |
| windows-1252 | Microsoft calls its coded character sets "code pages." Windows code page 1252 (a.k.a. "CP1252" or "WinLatin1") is an extension of iso-8859-1. |
Content-Type Charset Header and META Tags
Web servers send the client the MIME charset tag in the Content-Type header, using the charset parameter:
Content-Type: text/html; charset=iso-2022-jp
If no charset is explicitly listed, the receiver may try to infer the character set from the document contents. For HTML content, character sets might be found in <META HTTP-EQUIV="Content-Type"> tags that describe the charset.
Example 16-1 shows how HTML META tags set the charset to the Japanese encoding iso-2022-jp. If the document is not HTML, or there is no META Content-Type tag, software may attempt to infer the character encoding by scanning the actual text for common patterns indicative of languages and encodings.
Example 16-1. Character encoding can be specified in HTML META tags
<HEAD>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-2022-jp">
<META LANG="jp">
<TITLE>A Japanese Document</TITLE>
</HEAD>
<BODY>
...
If a client cannot infer a character encoding, it assumes iso-8859-1.
The Accept-Charset Header
There are thousands of defined character encoding and decoding methods, developed over the past several decades. Most clients do not support all the various character coding and mapping systems.
HTTP clients can tell servers precisely which character systems they support, using the Accept-Charset request header. The Accept-Charset header value provides a list of character encoding schemes that the client supports. For example, the following HTTP request header indicates that a client accepts the Western European iso-8859-1 character system as well as the UTF-8 variable-length Unicode compatibility system. A server is free to return content in either of these character encoding schemes.
Accept-Charset: iso-8859-1, utf-8
Note that there is no Content-Charset response header to match the Accept-Charset request header. The response character set is carried back from the server by the charset parameter of the Content-Type response header, to be compatible with MIME. It's too bad this isn't symmetric, but all the information still is there.