| [ LiB ] |
Extending Python, Lua, and Ruby
Extending is one of the super powers Python, Lua, and Ruby have to offer. Extending is basically the ability to combine code from two or more different languages into one running executable or script. Although this adds a layer of complexity to a project, it gives a developer the ability to pick and choose from the existing toolbox.
All of these languages are built around being extensible; extensibility is one of the features that has made them so prolific. The language documentation that comes with each includes a nifty sample and explanation of how to partner with other languages, so this section is more of a brief overview of the process.
Languages are extended for many different reasons. A developer may want to use an existing c library or port work from an old project into a new development effort. Often extensible languages are used as prototypes, and then profiling tools are used to see what parts of the code execute slowly, and where pieces should be re-written. Sometimes a developer will need to do something that just isn't possible in the main language, and must turn to other avenues.
Extending is mainly used when another language can do the job betterbetter meaning more efficiently or more easily. Most commonly, you will find these languages partnered with c and C++, where the Cs are running code that needs to be optimized for speed and memory.
Problems with Extending
As I've already mentioned, multilanguage development adds an extra layer of complexity. Particular problems with extending are as follows:
You must debug in two languages simultaneously.
You must develop and maintain glue code that ties the languages together (this might be significantly large amounts of code).
Different languages may have different execution models.
Object layouts between languages may be completely different.
Changes to one side of the code affect the other side, creating dependencies.
Functions between languages may be implemented differently.
Extended programs can also be difficult to debug. For instance, Ruby uses the GNU debugger, which can look at core dumps but still doesn't have breakpoints or access to variables or online source help. This is really different from the types of tools available for c and C++, where breakpoints and core dumps can be watched and managed during debug execution. Since the tools can differ between two languages, a developer may have to hunt through more than one debugger to find a problem. Also, because high-level language debuggers are usually more primitive, there is less checking during compile time, which could lead to missed code deficiencies.
There are some glue code packages that solve some of these problems. These are third-party programs that manage the creation of extended code; Simple Wrapper Interface Generator (SWIG, covered later in the chapter) is one example of such a package.
Though adding more than one language to a project gives you more options, as I said, it does add an extra level of complexity. When you add a language, you will need multiple compliers and multiple debuggers, and you will have to develop and maintain the glue code between the two languages. Whether to add a language is a tough management question, one that needs to be answered based on the needs of each particular project.
A final issue with having high-level code in a shipped product is that the code reveals much more about the source than does c or C++; this can make it more vulnerable to hacking. This doesn't mean that c or C++ cannot be hacked, just that if the variable names and function names are shipped in scripts with the game code in a high-level format, the game can be easier to break into or deconstruct.
Extending Python
There are a few built-in ways of integrating Python with C, C++, and other languages. Writing an extension involves creating a wrapper for c that Python imports, builds, and can then execute. Python also provides mechanisms for embedding, which is where c (or an equivalent) is given direct access to the Python interpreter. There are also a number of third-party integration solutions.
Writing a Python Extension
You must write a wrapper in order to access a second language via a Python extension. The wrapper acts as glue between the two languages, converting function arguments from Python into the second language and then returning results to Python in a way that Python can understand. For example, say you have a simple c function called function:
int function (int x)
{
/*code that does something useful*/
}A Python wrapper for function looks something like the following:
#include <Python.h>
PyObject *wrap_function(PyObject *self, PyObject *args)
{
int x, result;
if (!PyArg_ParseTuple(args, "i:function",&x))
return NULL;
result = function(x);
return Py_BuildValue("i",result);
}The wrapper starts by including the Python.h header, which includes the necessary commands to build a wrapper, and also a few standard header files (like stdio.h, string.h, errno.h, and dstlib.h).
NOTE
TIP
Python commands that are included with Python.h almost always begin with Py or py, so they are easily distinguished from the rest of the c code.
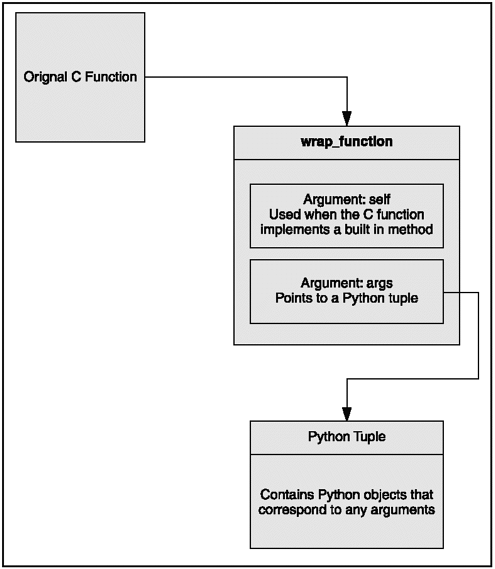
The PyObject wrapper wrap_function has two arguments, self and args (see Figure 12.2). The self argument is used when the c function implements a built-in method. The argsargument becomes a pointer to a Python tuple object containing the arguments. Each item of the tuple is a Python object and corresponds to an argument in the call's argument list.
Figure 12.2. The illustrated wrap_function
The small "i" in the i:functionline is short for int. If the function instead required a different type, you would need to use a different letter than "i":
i. For an integer.
I. For a long integer.
s. For a character string.
c. For a single character.
f. For a floating point number
d. For double
o. For an object
Tuple. Python tuples can hold multiple objects.
Together, PyArg_ParseTuple() and PyBuildValue() are what converts data between c and Python (see Figure 12.3). Arguments are retrieved with PyArg_ParseTuple, and results are passed back with Py_BuildValue. Py_BuildValue() returns any values as Python objects.
Figure 12.3. Data converting between c and Python
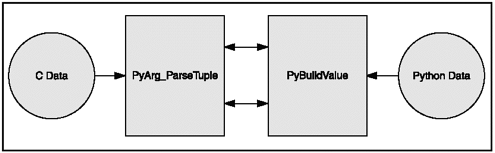
PyArg_ParseTuple() is a Python API function that checks the argument types and converts them into c values so that they can be used. It returns true if all arguments have the right type and the components have been stored in the variables whose addresses are passed. If a c function returns no useful argument (i.e. void), then the Python function must return None.
In the code snippet an ifstatement is also used. This structure is there just in case an error is detected in the argument list. If an error is detected, then the wrapper returns NULL.
Once a wrapper has been written, Python needs to know about it. Telling Python about the wrapper is accomplished with an initialization function. The initialization function registers new methods with the Python interpreter and looks like this:
Static PyMethod exampleMethods[] = {
{"function", wrap_function, 1},
{NULL, NULL}
};
void initialize_function(){
PyObject *m
m = Py_InitModule("example", "exampleMethods");
}Only after a wrapper and an initialization function exist can the code compile. After compilation, the function is part of Python's library directory and can be called at any time, just like a native Python module.
You can also use a setup file when importing a module. A setup file includes a module name, the location of the c code, and any compile tags needed. The setup file is then pre-processed into a project file or makefile.
The compile and build process for extending varies, depending upon your platform, environment, tools, and dynamic/static decision-making, which makes the Python parent documentation extremely valuable when you're attempting this sort of development.
Guido Van Rossum has a tutorial on extending and embedding Python within the language documentation, at http://www.python.org/doc/current/ext/ext.html.
The Python c API Reference manual is also extremely helpful if c or C++ is your target language. It's at http://www.python.org/dev/doc/maint22/api/api.html.
The last step in Python extension is to include any wrapped functions (in this case, function) in the Python code. Do this with a simple import line to initialize the module, like so:
import ModuleToImport
Then the function can be called from Python just like any other method.
ModuleToImport.function(int)
Embedding Python
Embedding in Python is where a program is given direct access to the Python interpreter, allowing the program the power to load and execute Python scripts and services. This gives a programmer the power to load Python modules, call Python functions, and access Python objects, all from his or her favorite language of comfort.
Embedding is powered by Python's API, which can be used in c by including the Python.h header file. This header
#include "Python.h"
contains all the functions, types, and macro definitions needed to use the API.
It is fairly simple to initialize Python in c once the Python header file is included (see Figure 12.4):
Figure 12.4. The embedding Python process

int main()
{
Py_Initialize();
PyRun_SimpleFile("<filename>");
Py_Finalize();
return();
}Py_Initialize is the basic initialization function; it allocates resources for the interpreter to start using the API. In particular, it initializes and creates the Python sys, exceptions, _builtin_, and _main_modules.
NOTE
CAUTION
Py_Initialize searches for modules assuming that the Python library is in a fixed location, which is a detail that may need to be altered, depending on the operating system. Trouble with this function may indicate a need to set the operating system's environment variable paths for PYTHONHOME or PYTHON PATH. Alternately, the module paths can be explicitly set using PySys_SetArgv().
The Pyrun_SimpleFilefunction is simply one of the very high-level API functions that reads the given file from a pointer (FILE *) and executes the commands stored there. After initialization and running any code, Py_Finalize releases the internal resources and shuts down the interpreter.
Python's high-level API functions are basically just used for executing given Python source, not for interacting with it in any significant way. Other high-level functions in Python's c API include the following:
Py_CompileString(). Parses and compiles source code string.
Py_eval_input. Parses and evaluates expressions.
Py_file_input. Parses and evaluates files.
Py_Main(). Main program for the standard interpreter.
PyParser_SimpleParseString(). Parses Python source code from string.
PyParser_SimpleParseFile(). Parses Python source code from file.
PyRun_AnyFile(). Returns the result of running PyRun_InteractiveLoop or PyRun_SimpleFile().
PyRun_SimpleString(). Runs given command string in _main_.
PyRun_SimpleFile(). As PyRun_SimpleString except source code can be read from a file instead of a string.
Py_single_input. Start symbol for a single statement.
PyRun_InteractiveOne(). Read and execute a single statement from an interactive device file.
PyRun_InteractiveLoop(). Read and execute all statements from an interactive device file.
PyRun_String(). Execute source code from a string.
PyRun_File(). Execute source code from a file.
The high-level tools really just scratch the surface, and Python's API allows memory management, object creation, threading, and exception handling, to name a few things. Other commonly used commands include PyImport_ImportModule(), which is for importing and initializing entire Python modules; PyObject_GetAttrString(), which is for accessing a given modules attributes; and PyObject_SetAttrString(), which is for assigning values to variables within modules.
Third-Party Integration
So what happens when there is a large integration project and some 100+ c functions must be gift-wrapped for Python? This can be a time-consuming, tedious, error-prone project. Imagine now that the library goes through a major update every four to six months, and each wrapper function will need to be revisited. Now you know what job security looks like!
Luckily, there are other options available for extension besides wrappers. SWIG, for instance, is an extension wrapper designed to make extension easier. It can be used to generate interfaces (primarily in C) without having to write a lot of code. Another option is Sip, a relative of SWIG, which focuses on C++. The Boost.Python library is yet another tool that can be used to write small bits of code to create a shared library. Of these three, SWIG is the most popular, probably because it plays well not only with C, C++, Python, and Ruby, but also with Perl, Tcl/Tk, Java, and C#. SWIG is copyrighted software, but it is freely distributed. It is normally found on UNIX but will also operate on Win32 OSs.
SWIG automates the wrapper process by generating wrapper code from a list of ANSI c functions and variable declarations. The SWIG language is actually fairly complex and very complete. It supports preprocessing, pointers, classes, inheritance, and even C++ templates.
SWIG is typically called from a command prompt or used with NMAKE. Modules can be compiled into a DLL form and then dynamically loaded into Python, or they can be set up as a custom build option in MS Development Studio. SWIG can be found online at Sourceforge (http://swig.sourceforge.net/), and Boost.Python, by David Abrahams, can be found online at Python.org (http://www.python.org/cgi-bin/moinmoin/boost_2epython).
Extending Lua
Lua was built to partner with other languages, and it can be extended with functions written in c just as Python can. These functions must be of the lua_CFunction type:
typedef int (*lua_CFunction) (lua_State *L);
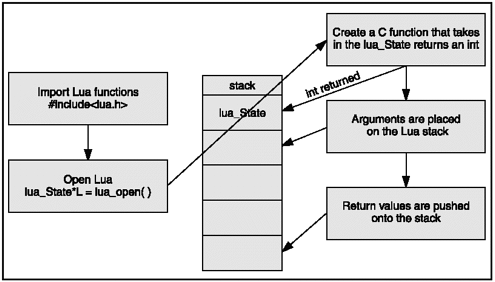
A c function receives a lua state and returns an integer that holds the number of values that must return to lua (see Figure 12.5). The c function receives arguments from lua in its stack in direct order. Any return values to lua are pushed onto the stack, also in direct order.
Figure 12.5. Representation of Lua and c partnership
When registering a c function to Lua, a built-in macro receives the name the function will have in lua and a pointer to the function, so a function can be registered in lua by calling the lua_register macro:
lua_register(L, "average", MyFunction);
Values can be associated with a c function when it is created. This creates what is called a C closure. The values are then accessible to the c function whenever it is called. To create a c closure, first push the values onto the stack, and then use the lua_pushcclosure command to push the c function onto the stack with an argument containing the number of values that need to be associated with the function:
void lua_pushcclosure (lua_State *L, lua_CFunction MyFunction, int MyArgument);
Whenever the c function is called, the values pushed up are located at specific pseudo-indices produced by a macro, lua_upvalueindex. The first value is at position lua_upvalueindex(1), the second at lua_upvalueindex(2), and so on.
Lua also provides a predefined table that can be used by any c code to store whatever lua value it needs to store. This table is a registry and is really useful when values must be kept outside the lifespan of a given function. This registry table is pseudo-indexed at LUA_REGISTRYINDEX. Any c library can store data into this table.
Extending Ruby
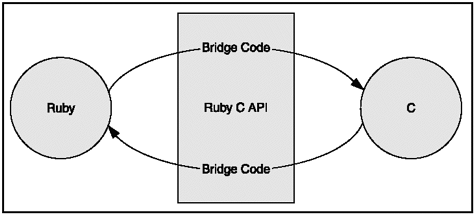
Extending Ruby in c is accomplished by writing c as a bridge between Ruby's c API and whatever you want to add on to Ruby (see Figure 12.6). The Ruby c API is contained in the c header file ruby.h, and many of the common API commands are listed in Table 12.2.
Figure 12.6. The Ruby c API
Ruby and c must share data types, which is problematic when Ruby only recognizes objects. For c to understand Ruby, some translation must be done with data types. In Ruby, everything is either an object or a reference to an object. For c to understand Ruby, data types must be pointers to a Ruby object or actual objects. You do so by making all Ruby variables in c a VALUEtype. When VALUE is a pointer, it points to one of the memory structures for a Ruby class or object structure. VALUE can also be an immediate value such as Fixnum, Symbol, true, false, or nil.
A Ruby object is an allocated structure in memory that contains a table of instance variables and other class information. The class is another allocated structure in memory that contains a table of the methods defined for that class. The built-in objects and classes are defined in the c API's header file, ruby.h. Before wrapping up any Ruby in C, you must include this file:
#include "ruby.h"
You must define a c global function that begins with Init_ when writing new classes or modules. Creating a new subclass of Ruby's object looks like the following:
void Init_MyNewSubclass() {
cMyNewSubclass = rb_define_class("MyNewSubclass", rb_cObject);
}Objectis represented by rb_cObject in the ruby.h header file, and the class is defined with rb_define_class. Methods can be added to the class using rb_define_method, like so:
void Init_MyNewSubclass() {
cMyNewSubclass = rb_define_class("MyNewSubclass", rb_cObject);
rb_define_method(cMyNewSubclass, "MyMethod", MyFunction, value );
}Ruby and c can also directly share global values. This is accomplished by first creating a Ruby object in C:
VALUE MyString; MyString = rb_str_new();
Then bind the object's address to a Ruby global variable:
Rb_define_variable("$String", &MyString);Now Ruby can access the c variable MyString as $String.
You may run into trouble with Ruby's garbage collection when extending Ruby. Ruby's GC needs to be handled with kid gloves when c data structures hold Ruby objects or when Ruby objects hold c structures. You can smooth the way by writing a function that registers the objects, passing free(), calling rb_global_variable() on each Ruby object in a structure, or making other special API calls.
Once code has been written for an extension, it needs to be compiled in a way that Ruby can use. The code can be compiled as a shared object to be used at runtime, or it can be statically linked to the Ruby interpreter. The entire Ruby interpreter can also be embedded within an application. The steps you should take depend greatly on the platform on which the programming is being done; there are instructions for each method on the online Ruby library reference, at http://www.ruby-lang.org/en/20020107.html.
The c API, however, is quite large, and for English users the best source for documentation is likely the source code itself.
Type | API Command | Function |
|---|---|---|
char | rb_id2name() | Returns a name for the given ID |
ID | rb_intern() | Returns an ID for a given name |
int | Check_SafeStr() | For raising SecurityError |
int | OBJ_FREEZE() | Marks the given object as frozen |
int | OBJ_FROZEN() | For testing if an object is frozen |
int | OBJ_TAINT() | Marks the given object as tainted |
int | OBJ_TAINTED() | For testing if an object is tainted |
int | rb_block_given_p() | Returns true if yield would execute a block in the current context |
int | rb_cvar_defined() | Returns Qtrue if the given class variable name has been defined, otherwise returns Qfalse |
int | rb_safe_level() | Returns the current safe level |
int | rb_scan_args() | Scans the argument list and assigns them in a similar way to scanf |
int | rb_secure() | Raises SecurityError if level is less than or equal to the current safe level |
VALUE | rb_apply() | Function for invoking methods |
VALUE | rb_ary_entry() | Returns an array element at a given index |
VALUE | rb_ary_new() | Returns a new array |
VALUE | rb_ary_new2() | Returns a new (long) array |
VALUE | rb_ary_new3() | Returns a new array populated with the given arguments |
VALUE | rb_ary_new4() | |
VALUE | rb_ary_push() | Pushes a value onto the end of an array self |
VALUE | rb_ary_pop() | Removes and returns the last element from an array |
VALUE | rb_ary_shift() | Removes and returns the first element from an array |
VALUE | rb_ary_unshift() | Pushes a value onto the front of an array self |
VALUE | rb_call_super() | Calls the current method in the super class of the current object |
VALUE | rb_catch() | Equivalent to Ruby catch |
VALUE | rb_cv_get() | Returns class variable name |
VALUE | rb_cvar_get() | Returns the class variable name from the given class |
VALUE | rb_define_class() | Defines a new top-level class |
VALUE | rb_define_class_under() | Defines a nested class |
VALUE | rb_define_module() | Defines a new top-level module |
VALUE | rb_define_module_under() | Defines a nested module |
VALUE | rb_each() | Invokes the each method of the given object |
VALUE | rb_funcall() | Invokes methods |
VALUE | rb_funcall2() | Invokes methods |
VALUE | rb_funcall3() | Invokes methods |
VALUE | rb_gv_get() | Returns the global variable name |
VALUE | rb_gv_set() | Sets the global variable name |
VALUE | rb_hash_aref() | Returns element corresponding to given key |
VALUE | rb_hash_aset() | Sets the value for a given key |
VALUE | rb_hash_new() | Returns a new hash |
VALUE | rb_iterate() | Invokes method with given arguments and block |
VALUE | rb_ivar_get() | Returns the instance variable name from the given object |
VALUE | rb_ivar_set() | Sets the value of the instance variable name in the given object to a given value |
VALUE | rb_iv_get() | Returns the instance variable name |
VALUE | rb_iv_set() | Sets the value of the instance variable name |
VALUE | rb_rescue() | Executes until a StandardError exception is raised, then executes rescue |
VALUE | rb_str_dup() | Returns a new duplicated string object |
VALUE | rb_str_cat() | Concatenates length characters on string |
VALUE | rb_str_concat() | Concatenates other on string |
VALUE | rb_str_new() | Returns a new string initialized with length characters |
VALUE | rb_str_new2() | Returns a new string initialized with null-terminated c string |
VALUE | rb_str_split() | Splits a string at the given deliminator and returns an array of the string objects |
VALUE | rb_thread_create() | Runs a given function in a new thread |
VALUE | rb_yield() | Transfers execution to the iterator block in the current context |
void | rb_ary_store() | Stores a value at a given index in an array |
void | rb_bug() | Terminates the process immediately |
void | rb_cvar_set() | Sets the class variable name in the given class to value |
void | rb_cv_set() | Sets the class variable name |
void | rb_define_alias() | Defines an alias in a class or module |
void | rb_define_attr() | Creates access methods for the given variable with the given name |
void | rb_define_class_variable() | Defines a class variable name |
void | rb_define_const() | Defines a constant in a class or module |
void | rb_define_global_const() | Defines a global constant |
void | rb_define_global_function() | Defines a global function |
void | rb_define_hooked_variable() | Defines functions to be called when reading or writing to variable |
void | rb_define_method() | Defines an instance method |
void | rb_define_module_function() | Defines a method in the given class module with the given name |
void | rb_define_readonly_variable() | Same as rb_define_variable except is read-only from Ruby |
void | rb_define_singleton_method() | Defines a singleton method |
void | rb_define_variable() | Exports the address of the given object that was created in c to the Ruby namespace as a given name |
void | rb_define_virtual_variable() | Exports a virtual variable to the Ruby namespace |
void | rb_exit() | Exits Ruby with the given status |
void | rb_extend_object() | Extends given object with module |
void | rb_fatal() | Raises a fatal exception |
void | rb_include_module() | Includes the given module into the class or module parent |
void | rb_iter_break() | Breaks out of the enclosing iterator block |
void | rb_notimplement() | Raises a NotImpError exception |
void | rb_raise() | Raises an exception |
void | rb_set_safe_level() | Sets the current safe level |
void | rb_sys_fail() | Raises a platform-specific exception |
void | rb_throw() | Equivalent to Ruby throw |
void | rb_undef_method() | Undefines the given method name in the given class or module |
void | rb_warn() | Unconditionally issues a warning message to standard error |
void | rb_warning() | Conditionally issues a warning message to standard error |
| [ LiB ] |