Scraping Google News


Scrape Google News search results to get at the latest from thousands of aggregated news sources.
![]()
Since Google added thousands of sources to its Google News [Tip #32] search engine, it's become an excellent source for any researcher. However, because you can't access Google News through the Google API, you'll have to scrape your results from the HTML of a Google News results page. This tip does just that, gathering up results into a comma-delimited file suitable for loading into a spreadsheet or database. For each news story, it extracts the title, URL, source (i.e., news agency), publication date or age of the news item, and an excerpted description.
Because Google's Terms of Service prohibits the automated access of their search engines except through the Google API, this tip does not actually connect to Google. Instead, it works on a page of results that you've saved from a Google News search you've run yourself. Simply save the results page as HTML source using your browser's File  Save As... command.
Save As... command.
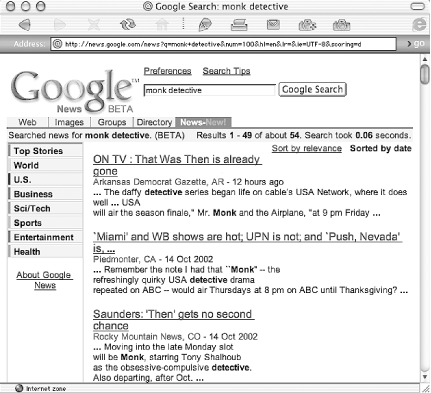
Make sure the results are listed by date instead of relevance. When results are listed by relevance some of the descriptions are missing, because similar stories are clumped together. You can sort results by date by choosing the "Sort By Date" link on the results page or by adding &scoring=d to the end of the results URL. Also make sure you're getting the maximum number of results by adding &num=100 to the end of the results URL. For example, Figure 4-2 shows results of a query for monk detective, hoping to find out more about the new popular feel-good detective show, "Monk."
The Code
#!/usr/bin/perl
# news2csv.pl
# Google News Results exported to CSV suitable for import into Excel
# Usage: perl news2csv.pl « news.html » news.csv print qq{"title","link","source","date or age", "description"\n};
my %unescape = ('<'=»'«', '>'=»'»', '&'=»'&',
'"'=»'"', ' '=»' ');
my $unescape_re = join '|' =» keys %unescape;
my($results) = (join '', «») =~ m!(.*?)!mis;
$results =~ s/($unescape_re)/$unescape{$1}/migs; # unescape HTML
$results =~ s![\n\r]! !migs; # drop spurious newlines while ( $results =~ m!(.+?)(.+?) - (.+?)(.+?)!migs ) {
my($url, $title, $source, $date_age, $description) =
($1||'',$2||'',$3||'',$4||'', $5||'');
$title =~ s!"!""!g; # double escape " marks
$description =~ s!"!""!g;
my $output =
qq{"$title","$url","$source","$date_age","$description"\n};
$output =~ s!!!g; # drop all HTML tags
print $output;
}
Figure 4-2. Google News results for "monk detective"
Running the Script
Run the script from the command line, specifying the Google News results HTML filename and name of the CSV file you wish to create or to which you wish to append additional results. For example, using news.html as our input and news.csv as our output:
$ perl news2csv.pl « news.html » news.csv
Leaving off the » and CSV filename sends the results to the screen for your perusal.
The Results
The following are some of the 54 results returned by a Google News search for monk detective and using the HTML page of results shown in Figure 4-2:
"title","link","source","date or age", "description" "ON TV : That Was Then is already gone", "http://www.nwanews.com/adg/story_style.php?storyid=9127", "Arkansas Democrat Gazette, AR", "12 hours ago", " ... The daffy detective series began life on cable«92»s USA Network, where it does well ... USA will air the season finale,"" Mr. Monk ... " "`Miami' and WB shows are hot; UPN is not; and `Push, Nevada' is, ... ", "http://www.bayarea.com/mld/bayarea/entertainment/television/...", "Piedmonter, CA", "14 Oct 2002", " ... Remember the note I had that ``Monk'' -- the refreshingly quirky USA detective dramarepeated on ABC -- would air Thursdays ... " ... "Indie Film Fest hits New Haven", "http://www.yaledailynews.com/article.asp?AID=19740", "Yale Daily News", "20 Sep 2002", " ... The Tower of Babble,"" directed by Beau Bauman '99, and ""Made-Up,"" which was directed by Tony Shalhoub DRA '80, who also stars in the USA detective show ""Monk."". ... "
(Each listing actually occurs on its own line; lines are broken and occasionally shortened for the purposes of publication.)
Tiping the Tip
Most of this program you want to leave alone. It's been built to make sense out of the Google News formatting. But if you don't like the way the program organizes the information that's taken out of the results page, you can change it. Just rearrange the variables on the following line, sorting them any way you want them. Be sure to you keep a comma between each one.
my $output =
qq{"$title","$url","$source","$date_age","$description"\n};
For example, perhaps you want only the URL and title. The line should read:
my $output =
qq{"$url","$title"\n};
That \n specifies a newline, and the $ characters specify that $url and $title are variable names; keep them intact.
Of course, now your output won't match the header at the top of the CSV file, by default:
print qq{"title","link","source","date or age", "description"\n};
As before, simply change this to match, as follows:
print qq{"url","title"\n};
« Previous Next »